1. Introduction
In order to predict feasible human grasps, we introduce GanHand, a multi-task GAN architecture that given solely one input image: 1) estimates the 3D shape/pose of the objects; 2) predicts the best grasp type according to a taxonomy with 33 classes [18]; 3) refines the hand configuration given by the grasping class, through an optimization of the 51 parameters of the MANO model.
- 실현가능한 사람의 움켜쥠을 예측하기 위해 하나의 input image만이 주어지는 구조의 multi-task GAN인 Ganhand를 소개한다.
1) 물체의 3D shape/pose 추정
2) 33개의 분류(손의 움켜쥠 형태를 33가지로 분류해둠)에 따른 best grasp type 예측
3) grasping class에서 제공하는 hand configuration을 MANO model의 51개의 parameters를 최적화하여 개선
This process involves maximizing the number of contact points between the object and the hand shape model while minimizing the interpenetration. Interestingly, our generative model is stochastic, allowing to predict several grasps per object.
- 이 과정은 관통을 최소화 하면서 object 와 hand shape model 사이의 contact point의 수를 최대화 하는것을 포함하고 있다. 흥미롭게, 이 generative model은 확률적이어서 object마다 몇몇의 grasp를 예측한다.
Another key contribution of this paper is the YCB-Affordance dataset that we created to train our network. This dataset is based on the 58 household objects of the YCB dataset [11], whose 3D models we have manually annotated with a total of 367 plausible human grasps according again to the taxonomy in [18]. The grasps of 21 objects are then transferred to 92 video sequences, depicting scenes with one or several still objects captured by a moving camera. Only feasible grasps where the hand does not collide with other elements of the scene are selected. The total number of annotated frames is 133,936, with more than 28M of realistic grasps, being the largest dataset of human grasp affordances in real scenes built so far.
- 이 논문의 또 다른 key contribution은 network를 학습시키기 위해 만든 YCB-Affordance dataset 이다. 이는 YCB dataset의 58개의 가정용 물체에 기반하며 taxonomy에 따라 총 367개의 그럴듯한 human grasp로 3D model에 수동으로 주석을 달았다. 그런 다음 21개의 물체에 대한 움켜쥠이 92개의 비디오 시퀀스로 옮겨져 움직이는 카메라에 찍힌 하나 또는 여러 개의 정지된 물체가 있는 장면을 묘사한다. 손이 장면의 다른 요소와 충돌하지 않는 곳에서만 가능한 움켜쥠이 선택 된다. 주석이 달린 프레임의 총 수는 133,936개이며 2,800만개 이상의 realistic grasp을 포함하여 지금까지 구축된 실제 장면에서 가장 큰 데이터 셋이다.

3. YCB-Affordance Dataset
To train our network for grasp affordance prediction in multi-object scenes, we needed natural images showing multiple objects annotated with valid human grasps. We thus collected the first large-scale dataset that includes hand pose and shape for natural and realistic grasping in multi-object scenes.
- multi-object scene에서 grasp affordance 예측을 위해 network를 학습하려면, 유효한 human grasp로 주석이 달린 multiple object를 보여주는 자연스러운 이미지가 필요하다. 따라서 논문에서는 multi-object scene에서 자연스럽고 사실적인 움켜쥠을 위해 hand pose와 shape 모양을 포함하는 최초의 large-scale data를 수집했다.
3.1. Grasp annotation on 3D models
Realistic grasps were manually annotated to cover all possible ways to naturally pick up or manipulate the objects. We used the visual interface of the GraspIt simulator [44] to manually adapt the hand palm position and rotation, and each of the finger joint angles. We exploited its integration with the SMPL model [58] to directly retrieve the low-dimensional MANO representation and obtain posed and registered hand shape meshes. On average, we annotated the 3D models with 6 distinct grasps for symmetric objects such as cans or bottles, and up to 12 different grasps for more complex objects such as tools or cutlery. In total, we manually annotated 367 different fine-grained grasps that we also assigned to a grasp type within the 33-grasp taxonomy of [18]. This taxonomy was defined considering the position of the contact fingers, the level of power/precision tradeoff in the grasp and the position of the thumb.
- Realistic grasping은 물체를 자연스럽게 집거나 조작할 수 있는 모든 가능한 방법을 다루기 위해 수동으로 주석처리 되었다. 저자는 Grasplt simulator의 visual interface를 사용하여 손바닥의 위치와 회전, 그리고 각 손가락의 joint angle을 수동으로 조정했다. 그리고 SMPL 과의 통합을 활용하여 low-dimensional MANO 표현을 직접 검색하고 포즈가 취해진, 등록된 hand shape mesh를 얻었다. 평균적으로 캔이나 병과 같은 대칭 물체에 대해서는 6개의 구별된 grasp로 3D 모델에 주석을 달았고 도구나 식기와 같은 더 복잡한 물체에 대해서는 최대 12개의 서로 다른 grasp로 주석을 달았다. 전체적으로 367개의 세밀한 grasp를 annotate 했는데 이 중엔 [18]의 33-grasp taxonomy에서 grasp 유형도 포함하고있다. 이 taxonomy는 접촉 손가락의 위치, 쥐는 힘/정확도의 tradeoff 및 엄지 위치를 고려하여 정의되었다.
We then annotated rotational symmetries in all the objects from the YCB Object set considering each main axis. A rotational symmetry is represented by its order, which indicates the number of times an object can be rotated on a particular axis and results in an equivalent shape [15]. We took advantage of objects’ symmetry by simply rotating the hand around the axes, automatically extending the number of grasps e.g. repeating grasps along the revolution axis. Note that simple brute-force generation of grasps using GraspIt simulator only leads to a reduced set of grasps which maximize the analytical grasp score [19] but are not necessarily correct or natural, e.g. holding a knife by the blade or grasping a cup with 2 fingers. On the contrary, our YCB-Affordance dataset includes only realistic grasps, including hand shapes that GraspIt would never find such as those shown in Fig. 3, e.g. scissors grasp.
- 그런 다음 각 주축을 고려하여 YCB object set의 모든 object에서 rotational symmetric에 주석을 달았다. rotational symmetry는 특정 축에서 회전할 수 있는 횟수를 나타내는 순서로 표시되며 결과적으로 동일한 모양이 된다. 저자는 단순히 축을 중심으로 손을 회전시켜 회전 축을 따라 잡는 등의 움켜쥠 횟수를 자동으로 늘림으로써 물체의 대칭성을 활용했다. Grasplt simulator를 사용한 경우 정확하거나 자연스럽지는 않다. 예를 들면 칼날로 칼을 잡거나, 두 손가락으로 컵을 잡는다. 반대로, YCB-Affordance dataset는 fig 3 처럼 Grasplt이 절대 찾을 수 없는 손 모양을 포함하여 사실적인 grasping만 포함된다. 예) 가위 잡는것 / Grasplt은 왼쪽 3개와 같이 power grasp type은 잘 복구하지만 오른쪽과 같은 경우는 전혀 발견되지 않는 경우가 많다.
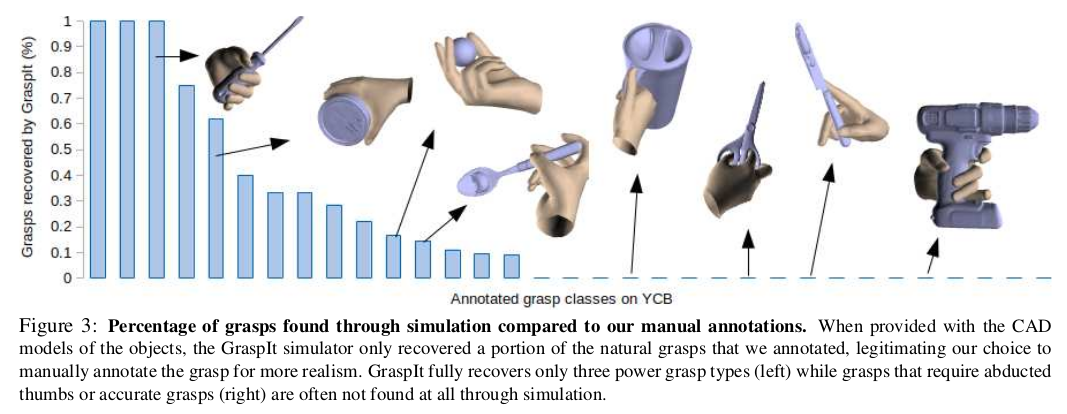
3.2. Grasp transfer to YCB scenes
The scenes in the YCB-Video Dataset [69] contain between 3 and 9 objects in close contact. Often, the placement of the objects makes them not easily accessible for grasping without touching other objects. Our goal was to annotate the scenes with valid and feasible grasps only, i.e. grasps for which the hand does not collide with other objects. To do so, we exploited the 6D pose annotations of the CAD models in camera coordinates available for the different objects. For a more complete 3D representation of the scene, we manually annotated the position of the table plane. In practice, this was manually done in the first frame of each video and propagated through the remaining frames using the motion of the camera in consecutive frames.
- YCB-Video Dataset의 scene에는 3~9개의 물체가 가까이 접촉하고 있다. 종종 물체의 위치들은 다른 물체를 만지지 않고 움켜쥘 수 있지 않게 한다.(즉, 한 물체를 만질 때 다른 물체와 충돌해버림) 저자의 목표는 유효하고 실현 가능한 grasp로만, 즉 손이 다른 물체와 충돌하지 않는 grasp로 scene에 주석을 다는 것이었다. 이를 위해 서로 다른 물체에 사용할 수 있는 CAD 모델의 6D pose annotation을 활용했다. scene의 보다 완전한 3D representation을 위해 table plane의 위치에 수동으로 주석을 달았다. 실제로 이는 각 비디오의 첫 번째 프레임에서 수동으로 수행하고, 연속된 프레임에서는 카메라의 움직임을 사용하여 나머지 프레임에 전파되었다.
We then transferred all the grasps annotated on the 3D CAD models to the real scenarios, using ground-truth 6D object poses and selecting only valid grasps for which the hand 3D mesh does not intersect with the objects 3D CAD models or the table plane. In most cases, several possible grasps remain valid for each object. However, the YCB-Video dataset does contain a few challenging scenes where an object is placed in a way that other objects occlude it too much for it to be grasped without any collision. In such cases, the object is considered as not reachable and left without grasp annotation. The final dataset contains 133,936 frames with more than 28M realistic grasp annotations, a suitable size to train deep networks.
- 그런 다음 GT 6D object pose 를 사용하고 hand 3D mesh가 3D CAD model 또는 table plane과 충돌하지 않는 유효한 grasp만 선택하여 3D CAD model에 주석을 단 것을 사용했다. 대부분의 경우, 각각의 물체에 대해 몇 가지 가능한 grasping이 유효하다. 그러나 YCB-Video 데이터는 충돌이 아닌 다른 물체가 너무 많이 가려 물체를 배치하는 몇 가지 어려운 장면이 포함되어 있다. 이러한 경우, 물체는 사용불가능 한 것으로 간주되고 grasp annotation이 없다. 최종 데이터 셋은 network를 학습하기에 적합한 크기인 28M 이상의 realistic grasp annotation이 있는 133,936 frame이 포함되어 있다.
4. Problem Formulation
Our goal is to predict how a human would naturally grasp one or several objects, given a single RGB image of these objects. This implies producing valid hand configurations showing several contact points with the target object but no intersection with other elements of the scene. Formally, given an image , we train a model that provides a hand pose and shape , and grasp type for every object of interest in :
where shape is the set of vertices of the hand mesh and is a coarse hand representation, within the 33-grasp taxonomy of [18]. Hand pose and shape parameters will be represented by the 51-DoF of the MANO model [58]. In the following we will jointly represent them by = {, }.
- 논문의 목표는 하나 또는 여러개의 물체에 대한 single RGB image가 주어졌을 때 어떻게 사람들이 물체를 자연스럽게 잡는지 예측하는 것이다. 이는 물체와의 여러 접점을 표시하지만 scene의 다른 요소와 충돌하지 않는 유효한 손 구성을 생성하는 것을 의미한다. 하나의 image I가 주어지면, hand pose P 와 shape V, 그리고 모든 관심 물체 I에 대한 grasp type C 를 제공하는 model M을 학습한다.
5. Method
- 하나의 RGB image를 input으로 하는 multi-task architecture인 GanHand에 대해 설명한다.
1) image 내의 known object에 대한 6D pose, unknown일 경우에는 3D pose + shape 추정
2) 각 object에 대한 best grasping type 예측
3) 예측된 grasp class에 의해 주어진 coarse hand configuration을 개선하여 손 끝을 object shape에 맞춤
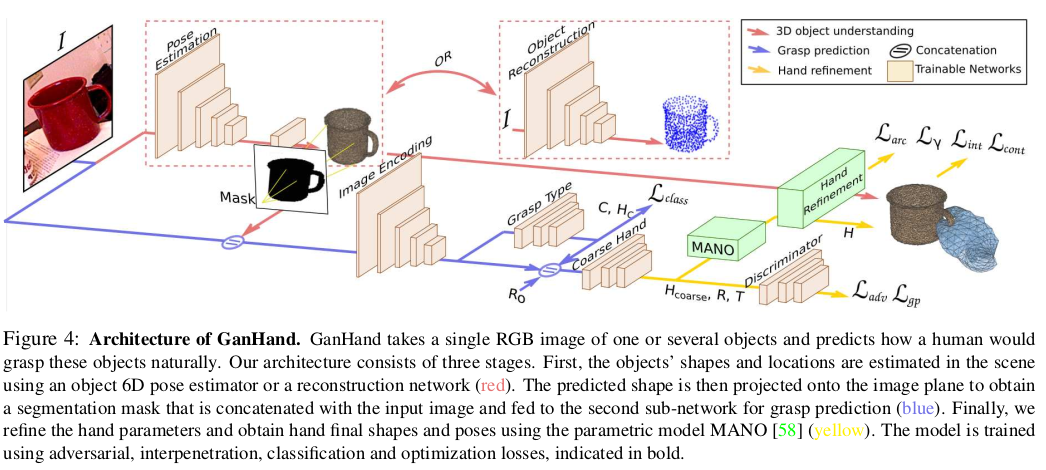
- 이 network는 3-stage로 구성되어있다.
- object 6D pose estimator나 reconstruction network를 사용하여 scene에서의 object의 shape과 location 추정
- 예측된 shape을 image plane에 projection하여 segmentation mask를 얻은 후 이를 input image와 concat하여 grasp 예측을 위해 두 번째 sub-network에 제공
- parametric model MANO를 사용하여 hand parameter를 개선하고, hand의 최종 shape과 pose를 얻음
- 이 모델은 adversarial, interpenetration, classification, optimization을 사용하여 학습된다.
5.1. 3D scene understanding
- 적절한 grasp를 예측하기 위해서는, 3D scene에서 geometry에 대한 이해가 필요하다. 이에 두 가지 상황을 고려한다.
- For multi-object scenes, we assume the observed objects are known and integrate the state-of-the-art object pose estimation method [29] to estimate their 6D pose, which we denote as T object . During training, one object is randomly selected at a time, its 3D shape is projected onto the image plane to obtain a segmentation mask that is then concatenated with the input image and fed to the grasp prediction network. The mask indicates which object has to be focused on while the original RGB image gives contextual information about the entire scene for a more realistic grasp. At test time, we run a forward pass for each detected object, obtaining a grasp prediction for each one of them.
- multi-object scene의 경우 관찰된 물체를 안다고 가정하고 sota object pose estimation method를 통합해 T라고 하는 물체의 6D pose를 추정한다. 학습 중에, 한 번에 한 물체를 무작위로 선택하고, 3D shape을 image plane에 projection하여 input image와 concat한 다음 grasp 예측 네트워크에 공급되는 segmentation mask를 얻는다. mask는 초점을 맞춰야 하는 물체를 나타내는 반면, 원본 RGB image는 realistic grasp를 위해 전체 scene 정보를 제공한다. 테스트시에는 감지된 각 물체에 대해 foward pass를 실행하여 각 물체에 대한 grasp prediction을 얻는다.
- For the simpler case of single-object scenes, we used the object reconstruction method AtlasNet [22] retrained on the synthetic ObMan dataset [28] to validate our approach. This reconstruction method does not require to know the object beforehand but is not reliable in case of multiple objects. Once the 3D shape and pose is known, we compute its segmentation mask and proceed as before.
- 더 간단한 single-object scene에 대해서는, object reconstruction method인 AtlasNet을 synthetic Obman dataset에 재학습하여 사용한다. 이 reconstruction method는 object에 대한 지식을 필요로 하지 않지만 object가 여러 개인 경우 신뢰할 수 없다. 3D shape과 pose를 알게되면, 이전처럼 segmentation mask를 계산하여 넘겨준다.
5.2. Predicting grasp type and coarse hand
Inspired by other approaches that tackle grasp recognition as a classification task [56], we propose a coarse-to-fine approach where grasp prediction is first addressed as a classification problem followed by a refinement stage. We predict the grasp class C that best suits the target object from a 33-grasp taxonomy [18]. To do so, we extract a representation of the input image using a pretrained and fine-tuned ResNet-50, followed by a classification network with a cross entropy loss .
- grasp recognition을 classification task로 다루는 다른 방식에 영향을 받아, 논문에서는 grasp prediction을 classification 문제로 먼저 다룬다음 refinement stage로 이어지는 coarse-to-fine approach를 제안한다. 저자는 33-grasp taxonomy로 부터 target object와 가장 맞는 grasp class C를 에측한다. 이는 input image에 대한 representation을 ResNet-50을 통해 추출하고, cross entropy loss 를 사용한 classification network가 뒤를 잇는다.
The predicted grasp C is associated to a representative hand configuration , centered on itself, that needs to be aligned in the camera coordinate system. For this purpose we represent the absolute translation of the hand w.r.t the camera as . Similarly we represent the absolute hand rotation as , where at training, is the rotation from a ground truth grasp with added noise. We then build a Fully Connected Network fed with {} that predicts {∆H, ∆T, ∆R}, to compute the absolute rigid pose of the hand, and its configuration , which is still a coarse estimate. We observed that using this strategy of predicting the increment for each of the parameters significantly speeds up convergence during training and improves results. At test time, we uniformly sample rotation candidates and run the forward pass for multiple proposals, keeping the top-scoring hand for each object.
- 예측된 grasp C는 hand configuration 와 연관이 있는데, 이는 카메라 좌표계에서 정렬되어야한다. 이를 위해 로 camera와 hand에 대한 absolute translation을 나타낸다. 비슷하게, absolute hand rotation을 로 나타내는데 학습 시에 는 noise가 추가된 GT grasp 에서의 rotation이다. 그 후에 {∆H, ∆T, ∆R}를 예측하기 위해{}를 input으로 하는 FC network를 구축하여 손의 절대 고정 자세와 이에 대한 대략적인 추정치로써 configuration 를 계산한다. 이러한 전략의 사용은 학습 중 수렴 속도의 증가와 결과 개선을 보임을 관찰하였다. 테스트 때에는, rotation 종류 를 uniform하게 샘플링하고 여러 개의 조건에 대해 forward pass를 실행하여 각 object에 대한 top-score를 유지한다.
5.3. Hand refinement for grasping
To improve the fingers location with respect to the object surface and consequently, the quality of the predicted grasp, we propose a new differentiable and parameter-free layer that allows to maximise grasp metric during training. This layer takes as input a MANO representation of and the 3D model of the object to be grasped, and returns a refined hand pose where the positions of the fingers are optimized to gracefully fit the object 3D surface. For each finger, we consider 3 rotations, one for each articulation. Following the kinematic chain, from the knuckle to the last joint, we bend/flex the finger within its physical limits, until it contacts the object.
- object surface에 대한 손가락 위치와 결과적으로 예측된 grasp의 quality를 개선하기 위해, 학습 중에 grasp metric을 최대화시키는 differentiable, parameter-free layer를 제안한다. 이 layer는 에 대한 MANO representation과 잡을 물체의 3D model을 input으로 사용하며, 손가락의 위치가 object 3D surface에 맞도록 최적화되는 정교한 hand pose를 반환한다. 손가락마다 각 관절에 대해 3번씩 회전을 고려한다. Kinematic chain을 따라 마지막 관절이 손가락이 물체에 닿을 때까지 물리적 한계 내에서 구부리거나 늘린다.
Formally, this is achieved by minimizing the distance D between the object vertices {} and the closest arc obtained when rotating an angle θ the finger’s vertices about the joint axes:
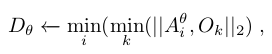
where is the arc obtained when rotating θ degrees the i-th vertex of the finger. Given this equation to compute the arc, we can then estimate the angle the finger needs to rotate around the first joint to collide with the object:
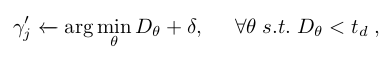
where δ (angle) is a hyper-parameter that controls the interpenetration of the hand into the object and hence the grasp stability (we analyze its effect in Sec. 7.1). Additionally, is an upper boundary threshold to consider when there is object-finger contact. In practice, we use = 2mm.
- 이는 object vertices {} 와 관절 축에 대해 손가락에 대한 vertex를 만큼 회전시킬 때 얻어진 가장 가까운 호 사이의 거리 D를 최소화함으로써 달성된다. 여기서 는 손가락의 i 번째 vertex를 θ 만큼 회전시켰을 때 얻어지는 호이다. 호를 계산하기 위해 이 방정식이 주어지면, 손가락이 물체와 충돌하기 위해 첫 번째 관절을 중심으로 회전해야 하는 각도 를 추정할 수 있다. 여기서 (angle) 은 물체에 대한 관통을 제어하는 하이퍼파라미터이며, grasping의 stability를 제어한다. (이에 대한 분석은 7.1에 포함) 또한, 는 물체-손가락 간 접촉이 있을 때 고려해야 할 upper bound threshold 이다. 실제로는 2mm를 사용한다. (접촉 시에는 2mm 이하로 distance 유지)
From these two equations we can define the following loss functions we will use to train our architecture:
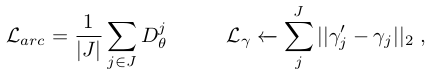
where |J| = 5 is the number of fingers. aims to minimize the hand-object distances when rotating the first joint of each finger, and directly operates on the estimated angles and compares them with the ground truth ones . This process can be sequentially performed for all three joints (knuckle, proximal and distal) of every finger, following the hand kinematic chain. In the results section we will provide results when optimizing 1, 2 or 3 joints per finger.
- 다음 두 방정식으로 아키텍처를 훈련하는 데 사용될 손실함수를 정의한다. 여기서 J는 5로, 손가락의 개수이다. 는 각 손가락의 첫 번째 관절을 회전할 때 손과 물체 사이의 거리를 최소화하는 것을 목표로 하고, 는 추정된 각도에 직접 연산을 수행하여 GT와 비교한다. 이 과정은 hand kinematic chain을 따라 모든 손가락의 세 관절 (knuckle, proximal and distal) 모두에 대해 순차적으로 수행될 수 있다. result section에서 각 손가락 마다 1, 2, 3개의 관절을 최적화할 때의 결과를 제공한다.
5.4. Training the model
- 앞에서는, 목표 물체를 향해 손가락을 점진적으로 향하게 하는 손실함수만 정의했다. 다음으로 사람과 같은 grasp 를 생성하고, 손과 scene 사이의 상호 관통을 방지하는 것을 목표로 하는 보완적인 손실함수를 정의한다.
First, following [28], we build a contact prior on the hand vertices that are more likely to be in contact with the target object and we minimize the distance between these vertices and the 3D object:
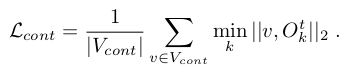
are computed as the vertices close to the object in at least 8% of the ground truth samples. They are mostly concentrated on the fingertips and the palm of the hand.
- 먼저, hand vertices에 대한 contact prior 를 구축하는데, 이는 target object 와 접촉할 가능성이 더 높은 vertex들이다. 그리고 이 vertex들과 3D object 사이의 distance를 최소화한다. ( 는 GT sample의 최소 8%에서 물체에 가까운 vertex로 계산된다.) 이는 대부분 손가락 끝과 손바닥에 집중되어 있다.
A very important loss (also considered in [28]) consists in penalizing the interpenetration between the hand and the object. If we denote by the set of hand vertices that are inside an object, we minimize their distance to their closest object surface point:
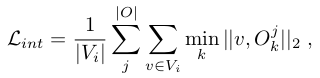
where |O| is the total number of objects found in the image.
- 매우 중요한 손실은 손과 물체 사이의 상호 관통에 페널티를 주는 것으로 구성된다. object 안에 있는 hand vertex set을 라 하면, 가장 가까운 물체의 surface point 까지의 거리를 최소화한다. 여기서 |O| 는 이미지에서 발견된 object의 총 개수이다.
We also penalize hand configurations that are below the table plane, by calculating the signed distance from each hand vertex to the table plane, and favoring this distance to be positive. Formally, if we represent the table plane by a point and a normal pointing upwards, this loss is:
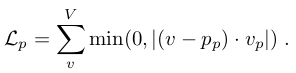
- 또한 각 손 vertex에서 table plane 까지의 signed distance를 계산하고 이 거리가 양수인 것을 선호하게 만들어 table plane 아래에 있는 hand configuration에 페널티를 준다. 수식으로는, table plane을 , 그리고 위쪽으로의 법선을 로 표현하면 loss는 다음과 같다.
To further enforce our network to generate anthropomorphic hands and realistic grasps we introduce a discriminator D trained using a Wasserstein loss [1]. Formally, let G be the trainable model defined so far, and let , , be the ground truth training samples, and , , interpolations between correct samples and predictions. Then, the adversarial loss is defined as:
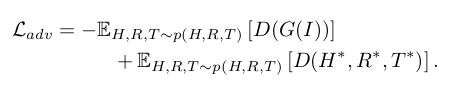
Additionally, to guarantee the satisfaction of the Lipschitz constraint in the W-GAN, we introduce a gradient penalty loss as proposed in [23].
- 사람 같은 손과 realistic grasp을 생성하는 것을 더 강화하기 위해, Wasserstein loss로 학습된 discriminator D를 도입한다. 수식으로는, G는 지금까지 정의된 학습 가능한 모델이고 , , 는 학습 샘플의 GT 이고, , , 는 정확한 샘플과 예측 사이의 interpolation이다. 그러면, adversarial loss는 다음과 같이 정의된다. 추가적으로, 기울기 페널티 손실을 도입했다.
6. Implementation Details
image encoder → ResNet-50
discriminator , hand refiner → 4-layer FC networks with ReLU, Xavier initialization
Input → 256 x 256
그리고 각 loss에 대한 scale 지정. (loss들의 linear combination이 최종 loss이다.)
7. Experiments
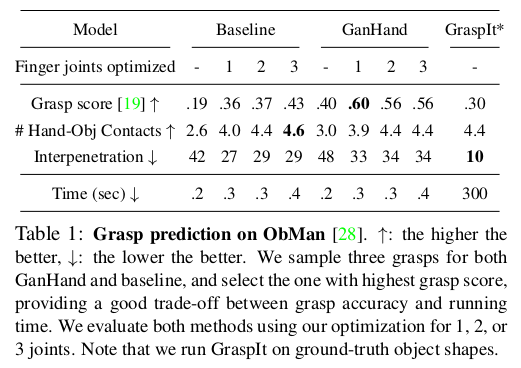
Baseline
- pre-trained ResNet-50으로 hand, rotation, translation에 대한 MANO representation를 바로 예측. 이 baseline은 fig 4의 파란색 sub-network 대체. 3D scene understanding과 hand refinement를 사용하지만, grasp taxonomy prediction X.
Evaluation metrics
- analytical grasp metric → grasping stability에 대한 metric (high)
- average number of contact finger → 몇 개의 손가락이 contact 되어 있는지 (high)
- hand-object interpenetration volume → hand와 object를 voxelization하여 volume 계산. 얼마나 관통했는지? (low)
- simulation displacement → 중력을 받을 때 물체 mesh의 simulation 변위 고려 (low)
- percentage of graspable objects → multi-object scene에서 유효한 grasp 비율 계산 (high)
7.1. Contribution of optimization layer
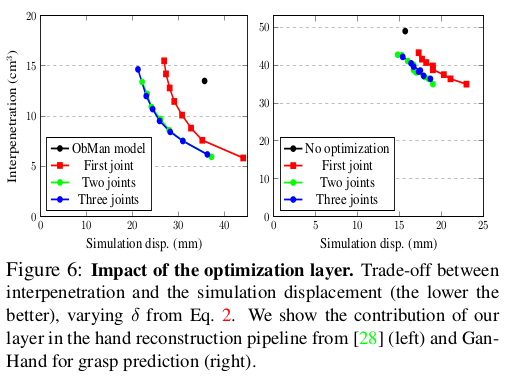
- 각 손가락 마다 몇 개의 관절을 optimization 하는지에 따라 결과가 달라졌고, 일반적으로 성능이 더 좋음. interpenetration과 simulation displacement 사이의 Trade-off figure 이다.
7.2. Validation on synthetic data
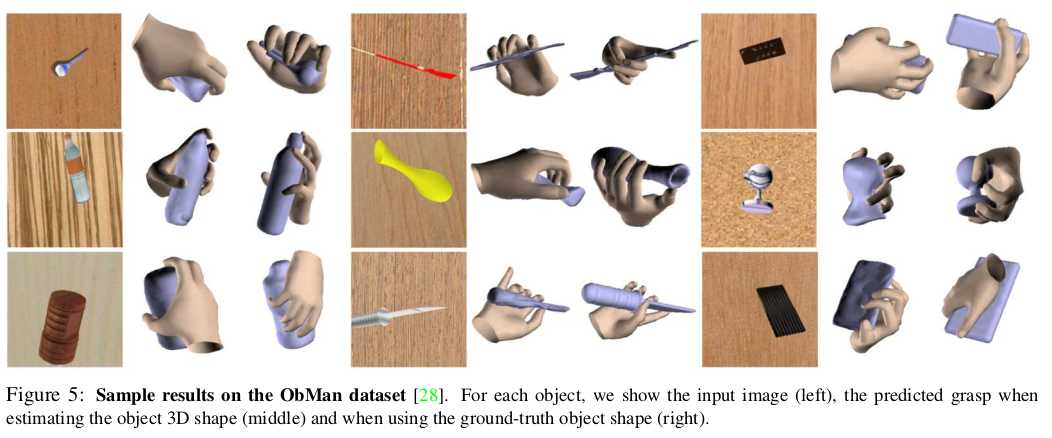
- Obman datset (학습도 obman에서)에서 전반적으로 GanHand가 결과가 좋고, Fig.5 는 왼쪽부터 input image, object 3D shape을 추정하여 사용하였을 때의 예측된 grasping, 그리고 GT object shape을 사용할 때이다.
7.3. Evaluation on YCB-Affordance

- YCB-Affordance dataset(학습도 ycb-affordance에서)에서 맨 아래 열은 잘 안된 케이스. 캔과 클램프의 pose가 정확하지 않고, 겹치는 그립이 생성.(왼쪽) 컵이 벽돌로 감지되어 잘못된 그립 예측(오른쪽)
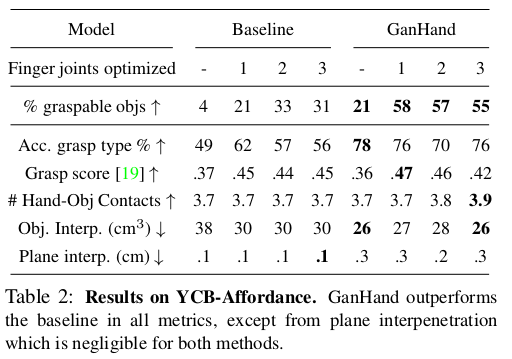
- numerical results는 좋은 결과를 보이고 있음.
8. Conclusion
We have introduced the problem of human grasp prediction in RGB images and proposed GanHand. To train GanHand, we built the YCB-Affordance, the first large-scale dataset of images annotated with plausible human grasps. We have validated our approach in both synthetic and real images showing that our model can robustly predict realistic human grasps.
- 저자는 RGB image에서 human grasp 예측 문제를 소개하고 GanHand를 제안했다. GanHand를 학습시키기 위해 그럴듯한 인간의 이해로 주석이 달린 최초의 large-scale dataset인 YCB-Affordance를 구축했다. 그리고 제안한 모델이 realistic human grasp을 강력하게 예측할 수 있음을 보여주기 위해synthetic image와 real image에서 network를 검증하였다.
- 학부생 때 만든 것이라 오류가 있거나, 설명이 부족할 수 있습니다.
Uploaded by N2T