Resolving 3D Human Pose Ambiguities with 3D Scene Constraints

Abstract
We show that current 3D human pose estimation methods produce results that are not consistent with the 3D scene. Our key contribution is to exploit static 3D scene structure to better estimate human pose from monocular images. The method enforces Proximal Relationships with Object eXclusion and is called PROX. To test this, we collect a new dataset composed of 12 different 3D scenes and RGB sequences of 20 subjects moving in and interacting with the scenes. We represent human pose using the 3D human body model SMPL-X and extend SMPLify-X to estimate body pose using scene constraints. We make use of the 3D scene information by formulating two main constraints. The inter-penetration constraint penalizes intersection between the body model and the surrounding 3D scene. The contact constraint encourages specific parts of the body to be in contact with scene surfaces if they are close enough in distance and orientation.
- 저자는 현재 3D human pose estimation이 3D scene과 일치하지 않는 결과를 생성한다는 것을 보인다. Key contribution은 static 3D scene structure를 활용해서 monocular image에서 human pose를 더 잘 추정하는 것이다. 이를 테스트하기 위해 12가지의 다른 3D scene과 20명의 subject가 scene과 interaction하는 RGB sequence로 구성된 새로운 dataset을 수집한다. 본 논문은 SMPL-X를 사용해서 human pose를 표현하고 SMPLify-X를 확장해서 scene constraints를 사용해 body pose를 estimation한다. 논문에서는 2가지 main constraints를 공식화해서 3D scene information을 활용한다. Inter-penetration constraints는 body model과 3D scene 사이의 intersection에 penalty를 부과한다. Contact constraint는 신체의 특정 part가 distance와 orientation이 충분히 가까운 경우 scene surface와 contact되도록 한다.
Technical Approach
Notation.
Scene 3D mesh : ,
Image : (Depth Image), (RGB Image)
Cam-to-world rigid transformation (Camera extrinsic parameter) :
SMPL-X : (Shape, Pose, Facial expressions, translation)
SMPL-X mesh :
Skeleton → 55개 // 22개는 main body (33개 → 3개 목(1개) + 눈(2개) + finger(각 15개))
Pose ,
( main body의 axis-angle, axis angle for face joints / 둘 다 각 joint 당 3-DOF임.)
( 는 양손의 finger articulation에 대한 pose space)
Joint를 kinematic tree로 변환하는 함수 :
따라서, 각 joint i에 대한 posed joint는 .
Human MoCap from Monocular Images
We name our method PROX for Proximal Relationships with Object eXclusion. We extend SMPLify-X to SMPLify-D, which uses both RGB and an additional depth input for more accurate registration of human poses to the 3D scene. We also extend PROX to use RGB-D input instead of RGB only; we call this configuration PROX-D.
- 논문의 방법은 Proximal Relationships with Object eXclusion(PROX)라는 방법이다. 저자는 SMPLify-X를 SMPLify-D 로 확장해서 사용하는데 이는 RGB와 depth input을 사용해서 3D scene에 더 정학환 human pose를 registration하는 방식이고, PROX에서도 단일 RGB대신 RGB-D를 쓰는데 이러한 구성을 PROX-D라고 한다.
Monocular image에 맞는 SMPL-X를 fitting하는 것을 optimization 문제로 취급하였고, objective function은 다음과 같다.
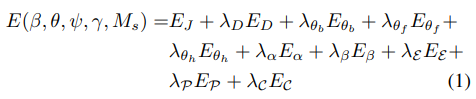
: RGB data term
: optional depth data term
, , , : L2 priors for hand pose, facial pose, facial expressions, body shape
(Penalizing deviation from the neutral state. : regularization term 용도로 쓰는듯.)
: prior penalizing extreme bending only elbows and knees
: VAE-based body pose prior
: body와 scene 사이의 contact을 encourage 해주는 term
: penetration penalty (self-penetration, human-scene inter-penetrations)
RGB data term
RGB Image 로 부터 estimate된 2D joint 와 pose 3D joints (SMPL-X)의 projection 사이에 대한 robust distant를 최소화 시킴. (i는 joint)
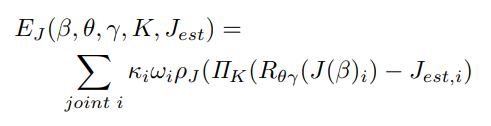
는 3D to 2D projection function이고 는 intrinsic camera parameter. 따라서 posed 3D joints를 projection 시킨 다음에 2D joint와의 loss임.
는 optimization을 위한 per-joint weight, 는 detection confidence(detection 에서의 noise를 설명하기 위함.)
는 robust Geman-McClure error function (noisy dection에 대한 down-weighting을 위함.)
Optional depth data term
visible body vertices 와 segmented point cloud (static scene이 아닌 body에만 속해있는) 사이의 discrepancy를 최소화 시킴. 이를 위해 Kinect-Once SDK의 segmentation mask를 사용함.
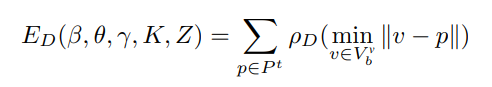
는 robust Geman-McClure error function ( 와는 거리가 먼 body vertices 에 대한 down-weighting을 위함.)
Contact Term
Human-world interaction에 대한 추론 없이 만으로는 physically implausible pose의 결과가 나타날 수 있음. 따라서, body part와 contact area 주변의 scene 사이의 contact과 proximity를 장려하기 위한 term인 를 추가함.
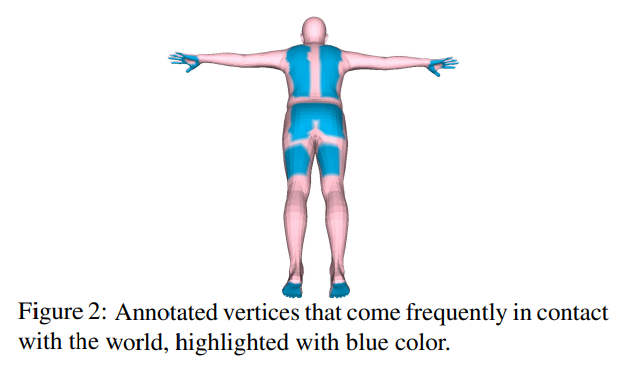
이를 위해 world에서 자주 contact되는 (걷다, 앉다, 터치하다의 액션에 포커스를 맞춤.) set of candidate contact vertices 를 annotate 하였음. 전체 1121개의 vertices를 annotate함. (725개 : hands, 62개 : thighs(허벅지), 113개 : gluteus(둔근) , 222개 : back, 194개 : feet)
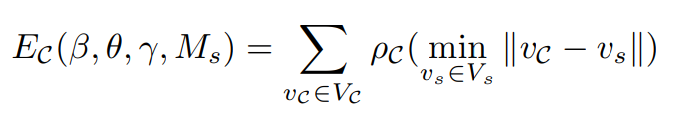
는 robust Geman-McClure error function ( 와는 거리가 먼 3D scene vertices 의 nearest vertices 에 대한 down-weighting을 위함.) → 거리가 먼데 nearest vertices일 경우 down-weight.
Penetration Term
직관적으로 두 개의 object가 같은 3D space를 share할 수 없다. 그러나, human pose estimation method는 self-penetration이나 3D object와 body 사이의 penetrating이 생길 수 있다. 따라서 penetration term을 위해 , 를 결합하였다.
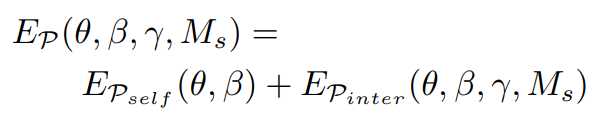
는 BVH(Bounding Volume Hierarchies) 를 사용해서 충돌하는 body triangle list를 감지하고 local conic 3D distance field를 계산한다. Penetration은 depth에 따라서 penalty를 받는다.
는 모든 penetrating vertices에 penalty를 주기 위한 term이다. SDF를 기반으로 사용함. 각 voxel 는 center 로 부터 scene mesh에서 정의되는 nearest surface point 까지의 거리와 normal 을 저장한다. 여기서 sign은 아래와 같이 voxel center로 부터 surface point까지의 orientation vector와 normal vector의 곱을 사용함.
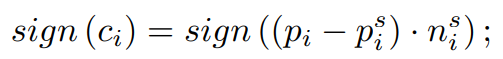
positive sign은 body vertex가 nearest scene object 외부에 있음을 의미하고 negative sign은 nearest scene 내부에 있으며 이는 penetration임을 의미한다.
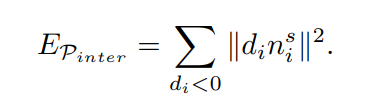
signed distance field.
distance field의 sign이 negative일 경우에 loss가 작용함. 이 떄 sdf * normal (해당 방향으로 얼마나 penetration되었는가? (약간 depth 개념으로 사용하는 듯 함.))
PiGraphs dataset
3D scene cans와 RGB-D videos를 포함하고 있음. 그러나 이는 몇 개의 limitation을 가지고있음. Color와 depth frame이 동기화되거나 sptial calibrated 되지 않아서 두 가지 frame 정보를 동시에 사용할 수 없다. 따라서, human pose가 noisy하거나 3D scene에서 잘 registeration되지 않아서 불확실하게 reconstruction되었음.
PROX dataset

12개의 indoor scene : 3개의 bedroom, 5개의 living room, 2개의 sitting booth, 2개의 offices.
20명의 subject (4명의 female, 16명의 male)
RGB-D camera를 동시에 써서 만들었고, 3D reconstruction을 위해서 Skanect라는 방식을 사용했다고 함.

Conclusion & Limitation
이 work는 human-world interaction에 집중하였고 RGB image에서 real static 3D scene와 human interacting을 capture하였다. 저자는 holistic model SMPL-X를 사용해서 interaction에 중요한 face, finger, body를 jointly modeling하였다. 본 논문에서 optimization framework (PROX) 에서 interaction-based human-world constraints가 더 realistic한 결과를 내는 것을 보였다.
현재 formulation의 문제점은 scene occlusion은 modeling하지 않았다는 것이다. 현재 2D part detector는 언제 joint가 occlusion되는지 indicate하지 않아서 부정확한 결과를 초래한다. scene structure를 아는 것이 무엇이 보이는지 아닌지를 추론할 수 있게 해준다.
다른 direction은 wholde body에 대한 implicit formulation을 사용해서 self-penetration과 body-scene interpenetration을 통합하는 것이다.
그리고 RGB에서 scene을 direct하게 추정하는 것, dynamic scene으로 확장하는 것, scene과 body deformation을 설명하는 것이다.
Generating 3D People In Scenes without People, CVPR’20
Human이 없는 3D scene을 input으로 받고 3D scene 상에서 naturally posed 3D human body를 생성하는 논문.


PROX-E dataset은 이런식으로 기존 PROX-D를 확장해서 object mesh의 categorization과 camera 각도를 조절, 즉 camera parameter에 약간의 noise를 줘서 이동 시키는 작업을 통해 데이터를 확장했다. 가 핵심 (사실 우리랑 하는 거랑 관련 X, 소개정도.)
MP3D-R dataset이라는 3D scene mesh에다가 human을 생성하는 작업도 함.
Original recording을 down sampling 하였다 → original scene 을 down sampling한 듯 한데, 그 방법에 대해선 언급 안 함. (일반적인 vertex sampling과는 좀 다르거나 아니면 비슷하게 하고 marching cube로 붙였을지도)
Compositional Human-Scene Interaction Synthesis with Semantic Control
Our goal is to synthesize humans interacting with a given 3D scene controlled by high-level semantic specifications as pairs of action categories and object instances, e.g., “sit on the chair”. The key challenge of incorporating interaction semantics into the generation framework is to learn a joint representation that effectively captures heterogeneous information, including human body articulation, 3D object geometry, and the intent of the interaction. To address this challenge, we design a novel transformer-based generative model, in which the articulated 3D human body surface points and 3D objects are jointly encoded in a unified latent space, and the semantics of the interaction between the human and objects are embedded via positional encoding. Furthermore, inspired by the compositional nature of interactions that humans can simultaneously interact with multiple objects, we define interaction semantics as the composition of varying numbers of atomic action-object pairs. We extend the PROX dataset with interaction semantic labels and scene instance segmentation to evaluate our method and demonstrate that our method can generate realistic human-scene interactions with semantic control.
- 논문의 목표는 action category와 object instance의 pair와 같은 (예를 들면 sit on the chair) high-level semantic specification에 의해 control되는 human을 생성하는 것이다. 이 때 human은 주어진 3D scene과 interaction하는 중. Generation framework에 interaction semantics를 통합하는 것의 key challenge는 human body나 3D object geometry, 그리고 interaction에서의 의도를 포함하는 여러 종류의 정보를 효과적으로 캡처하는 joint representation을 학습하는 것이다. 이 문제를 해결하기 위해 저자는 joint로 연결된 3D human body surface point와 3D object를 동시에 unified latent space에 encoding시키고 human과 object 사이의 interaction에 대한 semantic을 positional encoding을 통해 embedding 된다. 또한 사람이 동시에 여러 object와 interact하는 자연스러운 compositional interaction에 영감을 받아 다양한 수의 interaction semantics를 action-object pair로 정의한다. 저자는 PROX dataset을 interaction semantic label과 scene instance segmentation으로 확장하였음.

Compositional action을 받아서 그 action들을 전부 취하고 있는 mesh를 만들어냄.
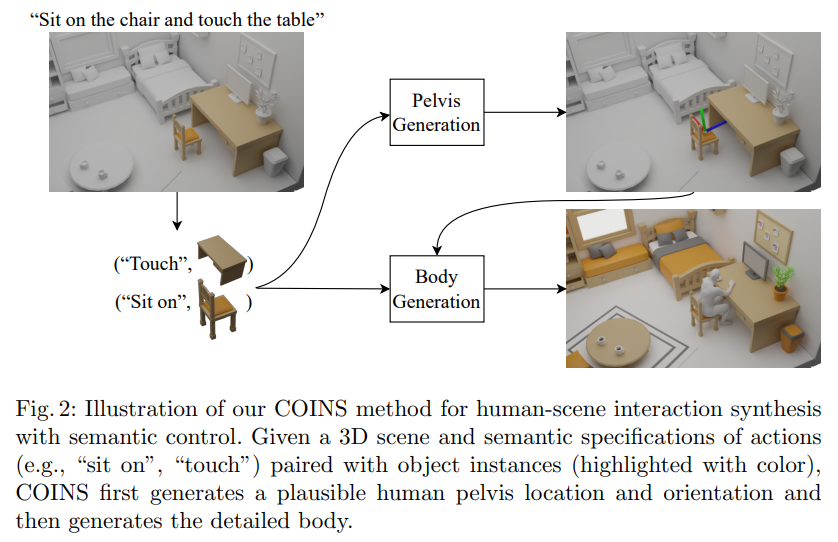
간단하게는 scene이 주어진 상태에서 action에 대한 semantic specification pair를 주면 그거에 맞는 human body mesh를 generation하는 task.
The binary contact features C ∈ {0, 1}^655 indicate whether each body vertex is in contact with scene objects [11].
논문에서는 Contact 정보를 2가지의 측면으로 사용함.
- Interaction Synthesis 할 때 contact feature라는 per vertex contact information를 같이 예측하고, 이를 optimization 방식으로 interaction을 더 improvement 시킨다.
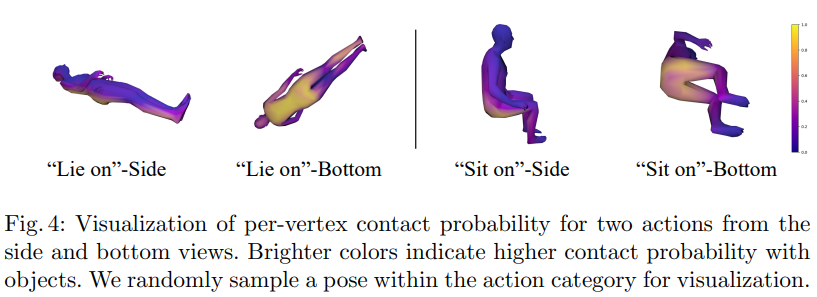
- Compositional Interaction generation 중에서 attention mechanism을 더 잘 활용하기 위해 논문의 방법에서 각 action에 따른 per-vertex contact probability라는 것을 사용하는데 예를들면 앉아있다. 라는 의미는 hip area 주변에서의 contact으로 characterize 시킨다. 라고 소개되어있음. 이를 기반으로 attention mechanism을 적용한다는데 우리랑 관련 X 소개 안함
PROX-S에서는 per-frame interaction semantic label을 (action-object pair 형태의) 추가함. Scene에서 manually instance segmentation함.
Interaction semantics를 annotation 하기 위해 VIA 라는 video annotation tool을 사용함. Interval 단위로 interaction을 action-noun pair로 specification 하는 tool.

PROX-S는 32K의 human-scene interaction frame을 포함하고 있고, 12 indoor scene에서 43개의 sequence를 포함한다. 이 중 8개의 scene은 training으로 사용하고 4개의 scene은 test로 사용한다. Training dataset에서는 17개의 다른 action을 들고있고, 42개 category의 interaction이 action-object pair로 존재함.
Uploaded by N2T