논문 링크 : https://arxiv.org/pdf/2008.04451.pdf

Abstract
Yet, human grasps are still difficult to synthesize realistically. There are several key reasons:
(1) the human hand has many degrees of freedom (more than robotic manipulators);
(2) the synthesized hand should conform to the surface of the object;
(3) it should interact with the object in a semantically and physically plausible manner.
- 여전히, human grasp는 현실적으로 만들기 어렵다. 이는 다음과 같은 이유 때문이다.
- Human hand는 robot hand보다 degrees of freedom이 크다. (MANO parameter 개수)
- 합성된 hand는 object surface와 일치해야한다.
- 의미론적으로 물리적으로 그럴듯한 방식으로 object와 interaction 해야한다.
Our insight is that every point in a three-dimensional space can be characterized by the signed distances to the surface of the hand and the object, respectively. We name this 3D to 2D mapping as Grasping Field, parameterize it with a deep neural network, and learn it from data. Specifically, our generative model is able to synthesize high-quality human grasps, given only on a 3D object point cloud. Furthermore, based on the grasping field representation, we propose a deep network for the challenging task of 3D hand-object interaction reconstruction from a single RGB image.
- 논문의 insight는 3차원 공간의 모든 점은 각각 손과 물체의 표면까지의 signed distance로 특징지을 수 있다는 것이다. 이러한 3D에서 2D로의 mapping을 Grasping Field라고 하고 neural network로 매개 변수를 지정하고 학습한다. 구체적으로, 논문의 generative model은 3D object point cloud가 주어졌을 때만 high-quality human grasp를 합성할 수 있다. 또한, grasping field representation을 기반으로, single RGB image로부터 3D hand-object interaction reconstruction이라는 어려운 작업을 위한 deep network를 제안한다.
1. Introduction
Our key observation is that human grasping is rooted in physical hand-object contact. Through this contact, humans are able to grasp and manipulate objects naturally. To this end, we propose a novel interaction representation that is based on regressing a continuous function that we call the Grasping Field. The grasping field maps any 3D point to a 2D space, where each dimension of the 2D space indicates the signed distance to the surface of the hand and the object respectively. Based on the grasping field representation, we propose a generative model, in which we generate plausible hand grasps given an object point cloud.
- 저자의 key observation은 human grasping이 물리적인 hand-object contact에 뿌리를 두고 있다는 것이다. 이러한 contact를 통해 인간은 object를 자연스럽게 grasp하고 조정할 수 있다. 이를 위해 Grasping Field라는 continuous function을 regressing하는 것을 기반으로 하는 새로운 interaction representation을 제안한다. Grasping field는 모든 3D point를 2D point에 mapping한다. 여기서 2D 공간의 각 차원은 손과 물체의 표먼까지 각각 signed distance를 나타낸다. Grasping field presentation을 기반으로 object point cloud가 주어지면 그럴듯한 hand grasp를 생성하는 generative model을 제안한다.
Contribution
(1) We propose the grasping field, a simple and effective representation for hand-object interaction
(2) Based on the grasping field, we present a generative model to yield semantically and physically plausible human grasps given a 3D object point cloud
(3) We further propose deep neural networks to reconstruct the 3D hand and object given an RGB input in a single pass
(4) We perform extensive experiments to show that our method outperforms the baseline [29] on 3D hand reconstruction and on synthesizing grasps that appear natural.
- Contribution은 다음과 같다.
- Hand-Object interaction에 대한 간단하고 효율적인 표현인 Grasping field 제안
- Grasping field를 기반으로, 3D object point cloud가 주어지면 의미론적이고 물리적으로 그럴듯한 human grasp를 얻는 generative model 제시
- Single pass로 RGB input이 주어지면 3D hand와 object를 reconstruction하는 deep neural network 제안
- 3D hand reconstruction과 자연스러워 보이는 grasp 합성에 있어 baseline을 능가하는 성능을 보여주기 위해 광범위한 실험 수행
3. Method
3.1. Grasping field
The grasping field (GF) is based on the signed distance fields of the object and the hand, formally defined as a function , mapping a 3D point to the signed distances to the hand surface and the object surface, respectively. In this way, the contact and inter-penetration relations between the hand and the object can be explicitly and efficiently represented. Specifically, the hand-object contact manifold is given by . The volume of hand-object inter-penetration is given by .
- GF는 object 와 hand 에 대한 signed distance field를 기반으로한다. 공식으로 표현하면 다음과 같이 정의되는데 이는 3D point를 hand surface와 object surface 각각에 대해 signed distance로 mapping 하는 함수이다. 이러한 방법으로, hand와 object 사이의 contact과 inter-penetration relation이 명시적으로, 효율적으로 표현될 수 있다. 구체적으로, hand-object contact manifold는 으로, hand-object inter-penetration는 으로 주어진다.
Signed Distance Field
내부에 있을 경우 -, 외부에 있을 경우 + 값을 가짐.
참고 사이트 : https://shaderfun.com/2018/03/25/signed-distance-fields-part-2-solid-geometry/
One can infer hand-object interaction in 3D space without the explicit hand and object surfaces. The learned GF can be considered as an interaction prior, which enables us to infer various grasping poses of the hand, only based on the 3D object. Using GF as the representation in hand-object reconstruction from images, we model the hand, the object, and the contact area by the implicit surfaces in a common space, largely improving the physical plausibility of the reconstruction. According to the aforementioned merits of the GF, we use it to address two tasks in this paper; i.e. hand grasp generation given 3D objects and hand-object reconstruction from RGB images.
- 위를 이용하면, Explicit hand object surface 없이 3D 공간에서 object와 hand의 interaction을 추론할 수 있다. 학습된 GF는 interaction prior로 고려될 수 있으며, 이를 통해 3D object만을 기반으로 손의 다양한 grasping pose를 추론할 수 있다. 이미지로부터 hand-object reconstruction의 representation으로 GF를 사용하여 공통 공간의 implicit surface로 hand, object, contact area를 모델링하여 reconstruction의 물리적인 타당성을 크게 향상시킨다. 앞서 언급한 GF의 장점에 따라 이 논문에서는 두 가지 작업을 처리하는 데 사용한다. 즉, 3D object가 주어지면 hand grasp 생성 및 RGB 이미지로부터 hand-object reconstruction이다.
3.2. Grasping field for human grasp synthesis
In this section, we show how to use GF to synthesize human grasps. Given an object point cloud, the goal is to generate diverse hand grasps that interact with the object in a natural manner.
Network architecture.
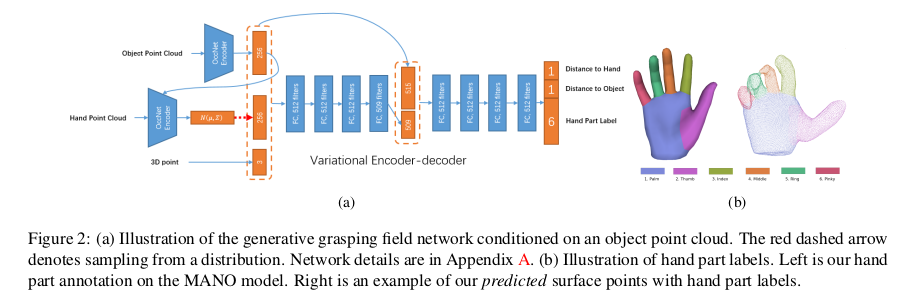
To extract features from point clouds, we use the PointNet encoder [68] with residual connection. The encoder-decoder network takes a query 3D point, and two point clouds of the hand and the object as input, and produces the signed distances of the query point to the hand and the object surfaces. In addition, the encoded object point cloud feature is fed into the hand point cloud encoder, leading to a hand distribution conditioned on the object. Note that this variational encoder-decoder network only requires both hand and object point clouds during the training. During inference, only the conditioning object point cloud and the query point are required. The hand features are sampled from the learned latent space, as in a standard VAE [38].
- Point cloud에서 feature를 추출하기 위해 residual connection이 있는 PointNet encoder를 사용한다. Encoder-Decoder network는 query 3D point와 hand, object의 point cloud를 input으로 사용하고 query point에서 hand와 object surface까지의 signed distance를 생성한다. 또한 encoding된 object cloud feature는 hand point cloud encoder에 사용되어 object에 대한 hand distribution을 유도한다. 이 variational Encoder-Decoder network는 학습 중에 hand, object point cloud만 필요로 한다. Inference 동안에는 conditioning object point cloud와 query point가 필요로 한다. Hand feature는 standard VAE에서와 같이 학습된 latent space에서 샘플링된다.
The reconstruction loss :
For each query point x, the input object point cloud and the input hand point cloud , the reconstruction loss is designed for the hand and object individually:
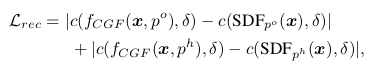
where is the grasping field network (Fig. 2a). and are the ground truth SDF for the hand and object, respectively. In addition, c(s, δ) := min(δ, max(−δ, s)) is a function to constrain the distance s within [−δ, δ]. δ is set to 1cm in all experiments.
- Query point x, input object point cloud , 그리고 input hand point cloud 에 대해 reconstruction loss는 hand와 object에 각각 따로 디자인 되어있고 아래와 같다. 여기서 는 grasping field network이다. 그리고 와 는 각각 hand,object SDF의 GT이다. 게다가 여기서 c(s, δ)는 distance s를 [−δ, δ] 사이의 간격으로 제한하는 역할을 한다. δ 는 1cm로 실험에서 세팅하였다.
KL-Divergence :
In order to generate new hand grasps, we use a KL-divergence loss to regularize the distribution of hand latent vector h, obtained from the hand point cloud encoder , to be a normal distribution. The loss is given by
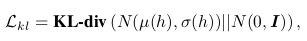
where denotes a standard high-dimensional normal distribution, μ and σ denotes mean and standard deviation. For generation, the hand latent vector h is sampled from a standard normal distribution.
- 새로운 hand grasp를 생성하기 위해 KL-divergence loss를 사용하여 hand point cloud encoder 에서 얻은 hand latent vector h에 대한 distribution을 정규 분포로 정규화한다. KL divergence loss는 다음과 같다. 생성을 위해 hand latent vector는 표준 정규 분포에서 샘플링된다.
Classification loss :
Besides predicting the signed distances of a query point, we also train the network to produce the hand part label of a query point to parse the hand semantically. To achieve this, we introduce a classification loss, which is given by a standard cross-entropy loss. The hand part annotation is based on the MANO model [74] as illustrated in Fig. 2b.
- Query point에 대한 signed distance를 예측하는 것 외에도, 의미론적으로 손을 분석하기 위해 query point에 대한 hand part label을 생성하도록 하는 network를 학습한다. 이를 위해 classification loss로 cross-entropy loss를 사용한다. 이는 Fig. 2b와 같이 MANO model을 기반으로 한다.
3.3. Grasping field for 3D hand-object reconstruction from a single RGB image
Here we address the challenging task of 3D hand-object reconstruction from a single RGB image, i.e. , in which is a 2D image. We model such a conditional GF by two types of deep neural networks and learn their parameters from data.
- Section 3.3에서는 single RGB image로 부터 hand-object reconstruction task를 다룬다. 즉, 이고, 여기서 는 2D image 이다. 논문에서는 이러한 조건부 GF를 두 가지 유형의 deep neural network로 모델링하고 데이터로부터 파라미터를 학습한다.
Network architecture.
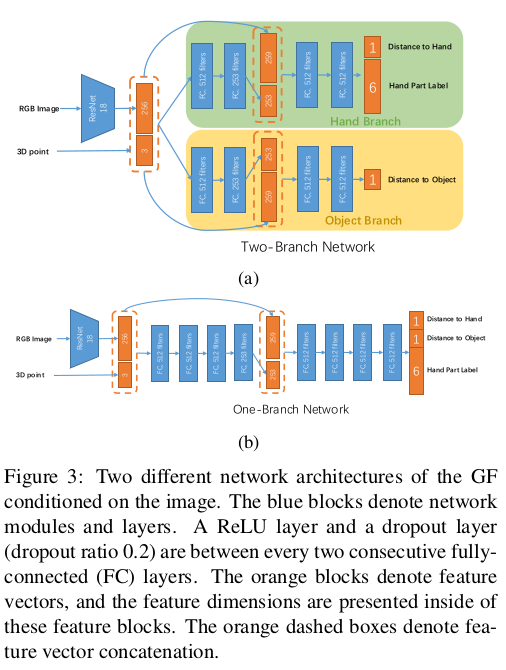
The two-branch network is employed (Fig. 3a), which addresses hand and object individually. We introduce contact and inter-penetration losses during the training to facilitate a better 3D reconstruction on the contact regions of the hand and the object. To introduce hand-object interactions in early stages, we propose a one-branch network (Fig. 3b), which uses the same image encoder and has the same number of layers with the two-branch model.
- 다음은 손과 물체를 개별적으로 처리하는 2-branch 네트워크가 사용된다. 논문에서는 손과 물체의 contact region에서 더 나은 3D reconstruction을 위해 학습 중 contact, inter-penetration loss를 도입한다. 초기 단계에서 hand-object interaction을 도입하기 위해 동일한 image encoder를 사용하고 2-branch 모델과 동일한 수의 레이어를 갖는 1-branch network를 제안한다.
The reconstruction loss :
For each query point x and the input image I, the reconstruction loss is designed for the hand and object individually, and is given by
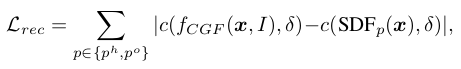
in which is our conditional grasping field network, and is the ground truth SDF for the component p (hand or object). c(s, δ) := min(δ, max(−δ, s)) is the thresholding function to constrain the distance s within [−δ, δ] as with the generative model proposed in Sec. 3.2.
- 각 query point x 및 input image I에 대해 reconstruction loss는 hand, object에 개별적으로 설계되었으며 이는 와 같다. 여기서 는 conditional grasping field network이고, 는 component p (hand 또는 object) 에 대한 ground truth 이다. c(s, δ) := min(δ, max(−δ, s))는 [−δ, δ] 사이로 distance s를 제한하는 thresholding 함수이다.
The inter-penetration loss :
To avoid surface inter-penetration between the reconstructed hand and object, we define the inter-penetration loss as
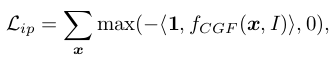
where 1 is a 2D one-vector, and denotes a dot product. This loss function actually penalizes the negative sum of predicted signed distances to the object and to the hand. If the hand and the object are separate and have no contact, the signed distance sum of every point in 3D space is always positive, and hence is ignored by our inter-penetration loss. On the other hand, if the hand and the object have inter-penetration, then this inter-penetration loss does not only penalize the points in the intersection volume, but also all 3D points in the space, indicating that the predicted han and object are incorrect. Compared to the inter-penetration methods in [26, 94], which only penalize the intersection volume, our loss applies stronger constraints.
- Reconstruction 된 hand, object 사이의 surface inter-penetration을 피하기 위해, interpenetration loss를 다음과 같이 정의한다. 여기서 1은 2D one-vector이고, 는 dot product이다. 이 loss function은 실제로 hand, object 까지의 예측된 signed distance의 negative sum에 페널티를 준다. 손과 물체가 분리되어 있고 접촉이 없는 경우, 3D space에서의 모든 point에 대해서 signed distance sum은 항상 양수이므로, 위에서 제시한 inter-penetration loss에 의해 무시된다. 반면에, 만약 hand와 object가 inter-penetration을 가지고 있는 경우, inter-penetration loss는 intersection volume(교차 볼륨)에서의 점 뿐만 아니라 공간의 모든 3D 점에도 페널티를 주어 예측한 hand와 object가 잘못된 것이라는 것을 나타낸다. 이전의 inter-penetration 방법과 비교하여 intersection volume에만 페널티가 적용되므로 loss는 더 강력한 제약 조건을 적용한다.
Contact loss :
Our proposed contact loss encourages hand-object contact, and is given by
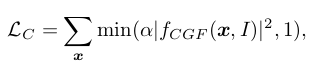
where α is a hyper-parameter. We can see that corresponds to the hand-object contact surface. Therefore, it ignores points with predicted grasping field , and only encourages points with to be the contact points. In our study, we empirically set α = 0.005 based on the hand-object interactions in the training data. Finally, we employ the same Classification loss as the one proposed in Sec. 3.2.
- 제안된 contact loss는 hand-object contact을 장려하고, 이는 다음과 같다. 여기서 는 hyper-parameter이다. 여기서, 이면 손과 물체의 접촉면에 해당함을 알 수 있다. 따라서 예측된 grasping field에서 일 경우 point를 무시하고, 일 경우에만 contact point가 되게끔 한다. 논문에서는 training data에서의 hand-object interaction을 기반으로 α = 0.005로 설정하였다. 마지막으로, Section 3.2. 처럼 동일한 Classification loss를 적용하였다.
3.4. From grasping field to mesh
With the trained grasping field conditioned on images or point clouds, one can compute the signed distances to the hand and object of a query 3D point. To recover the hand, object and their interactions, we first randomly sample a large number of points, and evaluate their signed distances. The point clouds belonging to the hand and the object can be selected, according to point-object signed distances close to zero. Then, the hand mesh and the object mesh are obtain by marching cubes [45].
- 이미지 또는 포인트 클라우드를 조건으로 학습된 grasping field를 사용하여 query 3D point에 대해 hand와 object 까지의 signed distance를 계산할 수 있다. Hand, object와 interaction을 복구하기 위해 먼저 많은 수의 점을 무작위로 샘플링하고 signed distance를 계산한다. 0에 가까운 point-object signed distance에 따라 손과 물체에 속하는 point cloud를 선택할 수 있다. 그런 다음 marching cube를 통해 hand, object mesh를 얻는다.
In addition, the hand mesh can be recovered by fitting the MANO [74] model to the hand point cloud. In this case, we can obtain hand segmentation, hand joint positions, and a compact representation of the hand simultaneously, according to the pre-defined topology in MANO. Denoting the MANO model by with the parameter β and θ representing hand shape and pose respectively, we minimize to recover the hand configuration, in which l denotes the 6 parts of hand, i.e. the palm and the 5 fingers, denotes the hand point cloud produced by our model, denotes the MANO hand mesh belonging to the hand part l, and d(·, ·) denotes the Chamfer distance [17, 61]. The hand segmentation is shown in Fig. 2b.
- 또한, MANO model을 hand point cloud에 피팅하여 hand mesh를 복구할 수 있다. 이 경우 미리 정의된 MANO topology에 따라 hand segmentation, joint 위치 그리고 간결한 표현을 동시에 얻을 수 있다. MANO 모델을 로 표시하고 parameter β와 θ는 hand shape, pose를 나타내므로 hand configuration을 복구하기 위해 를 최소화 시킨다. 여기서, 은 손의 6개의 부분(5개의 손가락, 손바닥)을 뜻하고 는 논문의 모델에 의해 얻어지는 hand point cloud이고, 는 hand part 에 속하는 MANO hand mesh 그리고 d(·, ·) 는 Chamfer distance이다.
4. Experiments
Dataset.
We use the synthetic ObMan dataset [29] to train our model. Due to the limited number of grasp types in the FHB dataset [19] and the HO-3D dataset [25], they are not suitable for training the generative model (see Appendix B). Instead, we use them to test the generalization ability of the generative model trained on the ObMan grasps. For the 3D reconstruction task, we also mainly use the ObMan dataset for training and testing. To test the effectiveness of our network on real-world images, however, we follow the same approach as [28] to train and test on the FHB dataset.
- 저자는 synthetic ObMan dataset을 사용하여 모델을 학습한다. FHB와 HO-3D의 grasp type의 수가 제한되어 있기 떄문에 generative model을 학습하는 데 적합하지 않다. 대신 ObMan grasp에서 학습된 모델의 일반화 능력을 테스트하는 데 사용한다. 3D reconstruction의 경우 training, tesing을 위해 주로 ObMan dataset을 사용한다. 그러나 real-world image에서 네트워크의 효율성을 테스트하기 위해 FHB에서 학습하고 테스트한다.
Evaluation metrics.
(1) Physical metrics:
a) Intersection volume and depth → hand, object mesh를 voxelize하여 겹치는 부분의 평면 사이의 최대 길이를 잰다. (low)
b) Ratio of samples with contact → 전체 데이터셋에 대해 샘플의 object와 hand가 접촉이 되었는지 (high)
c) Grasp stability → 중력을 적용시켜 물체의 질량 중심의 평균 변위 측 정 (low) (physics simulation)
(2) Semantic metric:
perceptual study를 통해 생성된 grasp의 자연스러움 평가 (high)
(3) 3D reconstruction quality:
Hand reconstruction quality를 평가하기 위해 reconstruct된 hand surface와 GT hand surface 사이의 chamfer loss 사용. (low)
4.1. Evaluation: Human grasps generation
Baseline
Grasping field의 decoder 부분을 MANO hand parameter를 regression하는 FC layer로 바꾼 네트워크를 사용. 그러면 3D object point cloud와 random sample이 주어지면 baseline model은 MANO parameter를 직접 생성한다.
Results
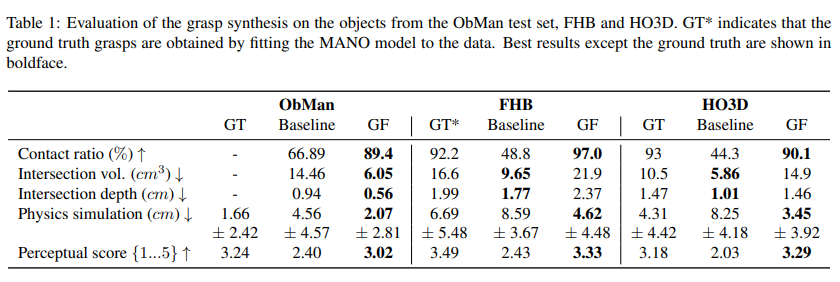
- Quantitative results. Baseline과 GF는 ObMan training set 에서만 학습되어 ObMan test set, FHB, HO3D 에서 테스트된다. GF가 전반적으로 좋은 결과를 보이고 있고, GT와도 comparable한 결과를 보인다. 그리고 물리적으로 그럴듯한 측면에서 보았을 때 FHB와 HO3D에서 GF가 더 나은 contact ratio와 grasp stability를 달성하였다.
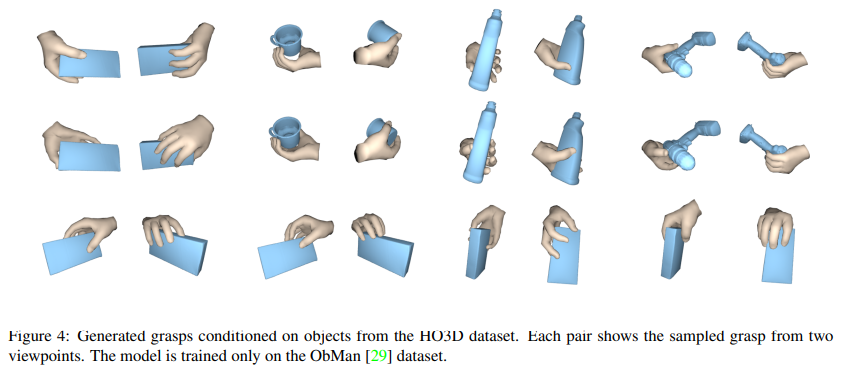

4.2. Evaluation: 3D hand-object reconstruction
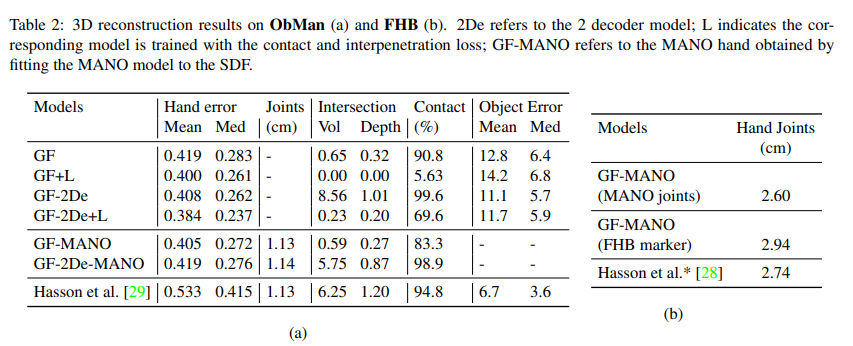
(a)는 ObMan, (b)는 FHB.
- Section 4.2에서는 section 3.3에 제시된 2가지의 network들에 대해 비교하는 내용이다. 여기서 2De는 2 decoder model임을 뜻한다. 두 아키텍처가 모두 괜찮은 결과를 보였지만, intersection error에서는 one decoder model이 효율적으로 hand-object interaction을 modeling함으로써 더 나은 성능을 달성하였다. 그리고 contact, interpenetration loss (+L)의 효과에 대해서도 표현하였다. 이 loss의 사용이 2 decoder model에서는 전반적으로 intersection volume과 depth를 감소시켰다. 그러나, one-decoder model의 경우 이러한 보조적인 학습 손실을 사용할 필요가 없다고 한다.(보면 Contact ratio가 급격하게 떨어짐을 볼 수 있고, 애초에 잘 되고 있음을 알 수 있음)
- MANO fitting을 사용하더라도 결과에 큰 영향을 미치지 않는 것을 보아, GF model이 이미 충분하게 hand reconstruction을 수행하고 있음을 알 수 있음.
- (b)에서는 MANO joint와의 비교인지, FHB marker와의 비교인지를 측정하는 것인데, GF가 FHB marker와의 optimization을 하지 않았기 때문에 loss가 크게 나왔고, MANO joint 즉, pseudo-gt와의 비교에서는 loss가 작게 나온 것을 보아 제안된 모델이 효과적이라는 것을 알 수 있음.
5. Conclusion and Discussion
In this work, we propose a novel representation for hand-object interaction, namely the grasping field. Learning from data, the GF captures the critical interactions between hand and object by modeling the joint distribution of hand and object shape in a common framework. To verify the effectiveness, we address two challenging tasks: human grasp generation given a 3D object and shape reconstruction given a single RGB image.
A limitation of our work is that there is no explicit modeling of the object functionality and human action in the current grasping field representation. In reality, a person holds an object differently based on different intentions. One promising future research direction is to incorporate human intention and object affordances into the grasping field for action specific grasps generation.
- 본 논문에서는 hand-object interaction에 대한 novel representation인 grasping field을 제안하였다. 데이터에서 학습된 GF는 hand와 object shape에 대한 joint distribution을 모델링하여 손과 물체 사이의 중요한 interaction을 포착한다. 효과를 검증하기 위해, 3D obejct가 주어졌을 때 human grasp generation, RGB image로부터의 shape reconstruction이라는 두 가지 task를 진행한다.
- 본 연구의 한계는 현재 grasp field representation에서 object 기능과 human action에 대한 explicit modeling이 없다는 것이다. 현실에서, 사람은 다른 의도에 따라 다르게 물체를 잡는 다는 것을 포함하지 않았다. Future work로는 action specific grasp generation을 위해 grasp field에 인간의 의도와 object affordance를 통합하는 것이다.
- 학부생 때 만든 것이라 오류가 있거나, 설명이 부족할 수 있습니다.
Uploaded by N2T