Abstract
Collecting 3D ground-truth data for hand-object interactions is costly, tedious, and error-prone. To overcome this challenge we present a method to leverage photometric consistency across time when annotations are only available for a sparse subset of frames in a video. Our model is trained end-to-end on color images to jointly reconstruct hands and objects in 3D by inferring their poses. Given our estimated reconstructions, we differentiably render the optical flow between pairs of adjacent images and use it within the network to warp one frame to another. We then apply a self-supervised photometric loss that relies on the visual consistency between nearby images.
- Hand-Object interaction을 위해 3D GT data를 수집하는 것은 비용이 많이들고, 지루하며, 오류 발생이 쉽다. 이 문제를 극복하기 위해 저자는 video에서 frame의 sparse subset만 annotation이 사용가능한 경우 시간에 따라 photometric consistency를 활용하는 방법을 제시한다. 모델은 RGB image로 부터 object, hand의 포즈를 추론함으로써 3D에서의 joint reconstruction을 end-to-end 방식으로 학습하였다. 추정된 reconstruction이 주어지면, 인접한 이미지 쌍 간의 optical flow를 미분가능하게 렌더링하고, 네트워크 내에서 이를 사용하여 한 프레임을 다른 프레임으로 warping한다. 그런 다음 주변 이미지 간의 시각적 일관성에 의존하는 self-supervised photometric loss를 적용한다.
1. Introduction
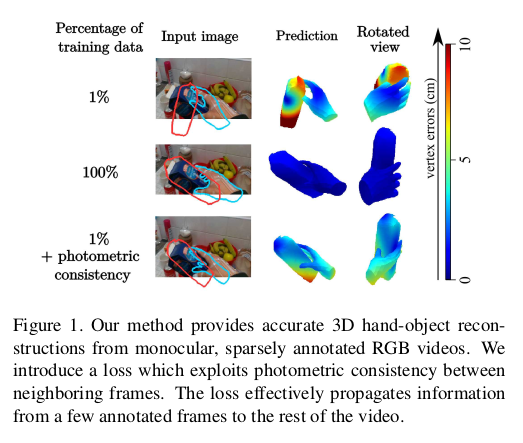
- 학습 데이터를 많이 사용할 수록 vertex error가 줄어듬을 볼 수 있고, 많이 사용하지 않았을 경우에도 이웃 frame과의 photometric consistency를 이용하여 error가 낮아짐을 볼 수 있다.
Our method aims at tackling these challenges and reduces the stringent reliance on 3D annotations. To this end, we propose a novel weakly supervised approach to joint 3D hand-object reconstruction. Our model jointly estimates the hand and object pose and reconstructs their shape in 3D, given training videos with annotations in only sparse frames on a small fraction of the dataset. Our method models the temporal nature of 3D hand and object interactions and leverages motion as a self-supervisory signal for 3D dense hand-object reconstruction. An example result is shown in Fig. 1.
- 논문에서 제시한 방법은 기존의 synthetic datasets은 아직 real datasets로 일반화하기 위한 현실성에 도달하지 못한다는 문제를 해결하고 3D annotation에 대한 엄격한 의존을 줄이는 것을 목표로 한다. 이를 위해 저자는 joint 3D hand-object reconstruction에 대한 novel weakly supervised method를 제안한다. 이 모델은 datasets의 작은 부분에 있는 sparse frame에만 annotation이 있는 training video를 input으로 하여 hand, object의 pose를 joint estimate하고 3D shape으로 reconstruction한다. 이 방법은 3D hand-object interaction의 시간적 특성을 모델링하고 3D dense hand-object reconstruction을 위한 self-supervisory signal로 motion을 활용한다. Fig. 1은 예시이다.
Contribution
We present a new method for joint dense reconstruction of hands and objects in 3D. Our method operates on color images and efficiently regresses model-based shape and pose parameters in a single feed-forward pass through a neural network.
- 3D에서 hand-object의 dense reconstruction을 위한 새로운 method를 제시한다. 이 방법은 컬러 이미지에서 작동하고 neural network를 통한 single feed-forward pass에서 model(MANO) 기반의 shape, pose parameter를 효율적으로 regression한다.
We introduce a novel photometric loss that relies on the estimated optical flow between pairs of adjacent images. Our scheme leverages optical flow to warp one frame to the next, directly within the network, and exploits the visual consistency between successive warped images with a self-supervised loss, ultimately alleviating the need for strong supervision.
- 인접한 이미지 쌍 사이의 추정된 optical flow에 의존하는 새로운 photometric loss를 소개한다. 논문에서의 방식은 optical flow를 활용하여 네트워크 내에서 직접 한 frame을 다음 프레임으로 warping하고 잘 warping된 이미지들 사이의 self-supervised loss를 사용해 visual consistency를 활용함으로써 궁극적으로 strong supervision의 필요성을 완화한다.
3. Method
We propose a CNN-based model for 3D hand-object reconstruction that can be efficiently trained from a set of sparsely annotated video frames. Namely, our method takes as input a monocular RGB video, capturing hands interacting with objects. We assume that the object model is known, and that sparse annotations are available only for a subset of video frames. To reconstruct hands, we rely on the parametric model MANO [38], which deforms a 3D hand mesh template according to a set of shape and pose parameters. As output, our method returns hand and object 3D vertex locations (together with shape and pose parameters) for each frame in the sequence. The key idea of our approach is to use a photometric consistency loss, that we leverage as self-supervision on the unannotated intermediate frames in order to improve hand-object reconstructions.
- 저자는 sparse annotation이 있는 video frame set에서 효율적으로 학습할 수 있는 3D hand-object reconstruction을 위한 CNN-based model을 제안한다. 이 방법은 single RGB video를 입력으로 받아 object와 interaction하는 hand를 캡처한다. Object model이 알려져 있고 sparse annotation이 video frame의 subset에 대해서만 사용할 수 있다고 가정한다. Hand reconstruction을 위해 저자는 shape, pose parameter set에 따라 3D hand mesh template를 변형하는 parametric model MANO에 의존한다. Output으로는 sequence의 각 프레임에 대해 hand, object의 3D vertex location을 shape, pose parameter와 함께 출력한다. 이 논문의 key idea는 hand object reconstruction을 개선하기 위해 annotation이 없는 중간 프레임에 대한 self-supervision으로 photometric consistency loss를 사용하는 것이다.
3.1. Photometric Supervision from Motion
As mentioned above, our method takes as input a sequence of RGB frames and outputs hand and object mesh vertex locations for each frame. We observe that the temporal continuity in videos imposes temporal constraints between neighboring frames. We assume that 3D annotations are provided only for a sparse subset of frames; this is a scenario that often occurs in practice when data collection is performed on sequential images, but only a subset of them is manually annotated. We then define a self-supervised loss to propagate this information to unlabeled frames.
- 위에서 언급했듯이, 모델은 RGB frame의 sequence를 input으로 사용하고 각 frame에 대한 hand, object vertex location을 출력한다. 저자는 비디오의 시간적 연속성이 인접 프레임 사이에 temporal constraint을 부과한다는 것을 관찰했다. 그리고 3D annotation이 프레임의 작은 subset에 대해서만 제공된다고 가정하는데, 이는 데이터 수집이 sequence image에 대해 수행될 때 실제로 자주 발생하는 시나리오이지만 그 중 일부만 수동으로 annotation을 달 수 있다. 그런 다음 label이 지정되지 않은 프레임에 이 정보를 전파하기 위해 self-supervised loss를 정의한다.
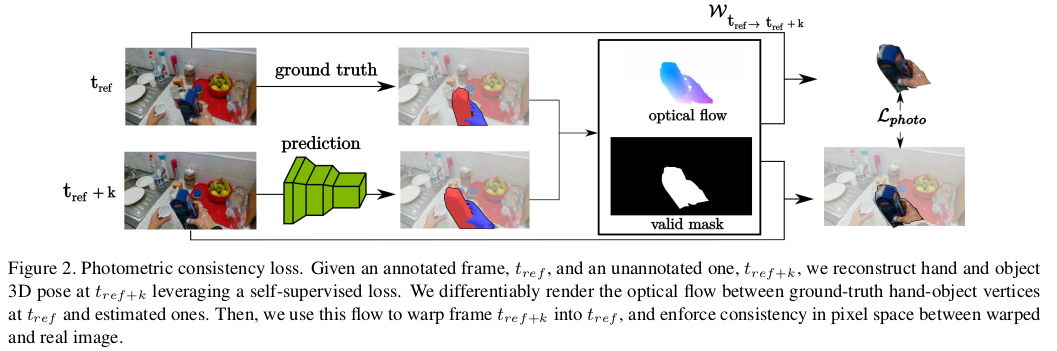
- Annotation이 있는 frame 와 없는 가 주어지면, self-supervised loss를 활용하여 에서의 hand, object 3D pose를 재구성한다. 저자는 에서의 GT hand-object vertex와 추정된 vertex사이의 optical flow를 differentiable하게 rendering한다. 그런 다음 이 flow를 사용하여 frame 를 로 warping하고 warping된 이미지와 실제 이미지 사이의 pixel 공간에 consistency를 적용한다.
Our self-supervised loss exploits photometric consistency between frames, and is defined in image space. Figure 2 illustrates the process. Consider an annotated frame at time , for which we have ground-truth hand and object vertices (to simplify the notation, we do not distinguish here between hand and object vertices). Given an unlabeled frame , our goal is to accurately regress hand and object vertex locations . Our main insight is that, given estimated per-frame 3D meshes and known camera intrinsics, we can back-project our meshes on image space and leverage pixel-level information to provide additional cross-frame supervision.
- Self-supervised lose는 frame 사이의 photometric consistency를 활용하며 이미지 공간에서 정의된다. Fig. 2는 process이다. 시점의 frame 는 annotation이 있는데, 이는 GT hand, object vertex 라고 명시한다. Label이 없는 frame 이 주어지면, 논문의 목표는 정확하게 hand, object vertex location 를 regression하는 것이다. 저자의 main insight는 frame마다 예측된 3D mesh가 주어지고 camera intrinsic을 알 경우, 이 mesh를 image space에 back-projection할 수 있고 pixel-level 정보를 활용하여 추가적인 cross-frame supervision을 제공할 수 있다는 것이다.
Given , we first regress hand and object vertices in a single feed-forward network pass. Imagine now to back-project these vertices on and assign to each vertex the color of the pixel they are projected onto. The object meshes at and share the same topology; and so do the hand meshes. So, if we back-project the ground-truth meshes at on , corresponding vertices from and should be assigned the same color. We translate this idea into our photometric consistency loss. We compute the 3D displacement (“flow”) between corresponding vertices from and . These values are then projected on the image plane, and interpolated on the visible mesh triangles. To this end, we differentiably render the estimated flow from to using the Neural Renderer [19]. This allows us to define a warping flow W between the pair of images as a function of .
- 이 주어지면, 먼저 hand object vertex 를 single feed-forward network pass에서 regression한다. 그리고 이 vertex를 에 back-projection하고 각 vertex에 투영되는 pixel에 색상을 할당한다. 와 에서의 object mesh와 hand mesh는 동일한 topology를 공유한다. 따라서 에서의 GT mesh를 에 back-projection하면, 와 동일하게 도 같은 색상이 할당되어야 한다. 저자는 이 아이디어로 photometric consistency loss를 정의하였다. 이를 위해 먼저 와 사이의 서로 상응하는 vertex 사이의 3D displacement인 “flow”를 계산한다. 그리고 이 value를 image plane에 projection하고 보이는 mesh triangle에 interpolation된다. 이를 해결하기 위해, neural renderer를 사용하여 에서 까지 추정된 flow를 미분가능하게 rendering한다. 이를 통해 에 대한 함수로 이미지 pair 사이의 warping flow W를 정의할 수 있다.
We exploit the computed flow to warp into the warped image , by differentiably sampling values from according to the predicted optical flow displacements. Our loss enforces consistency between the warped image and the reference one:
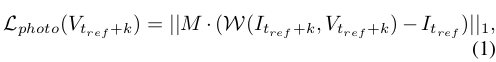
where M is a binary mask denoting surface point visibility.
- 저자는 예측된 optical flow displacement에 따라 에서 값을 미분가능하게 sampling하여 를 warping된 이미지 로 warping하게 위해 계산된 flow를 활용한다. 제시한 loss는 warping된 image와 참조 이미지 간의 consistency를 강화한다. 여기서 M은 surface point가 보이는지에 대한 binary mask이다.
loss 설명
- Warping flow를 통해 에서의 frame을 로 warping하고 왜곡된 이미지와 GT 이미지 사이의 pixel space에 consistency를 적용한다. 그리고 반대로도.
In order to compute the visibility mask, we ensure that the supervised pixels belong to the silhouette of the reprojected mesh in the target frame . We successively warp a grid of pixel locations using the optical flow to and from to and include only pixel locations which remain stable, a constraint which does not hold for mesh surface points which are occluded in one of the frames. Note that the error is minimized with respect to the estimated hand and object vertices .
- Visibility mask를 계산하기 위해 supervised pixel이 target frame 에서 reprojection된 mesh의 실루엣에 속하는지 확인한다. 저자는 로 부터 로, 그리고 로부터 로의 optical flow를 사용하여 pixel location에 대한 grid를 연속적으로 warping하고, 안정적으로 유지되는(즉, 한 프레임에서 가려진 mesh surface point는 포함되지 않는다는 제약 조건) pixel location만 포함한다. 추정된 hand, object vertex에 대해 error가 최소화 된다.
중간 정리
- Warping flow를 로 부터 로 계산하여 consistency loss를 적용하고, 그리고 로 부터 로도 계산하여 consistency loss 2개를 사용한다. 이는, 시점에서 hand-object만 자른 이미지를 optical flow를 이용하여 warping 시킨 hand-object 이미지와 의 hand-object 이미지와 비교하고 이 과정을 반대로도 한다. 최종적으로는 추정된 hand,object vertex에 대해 error가 최소화된다.
3.2. Dense 3D Hand-Object Reconstruction
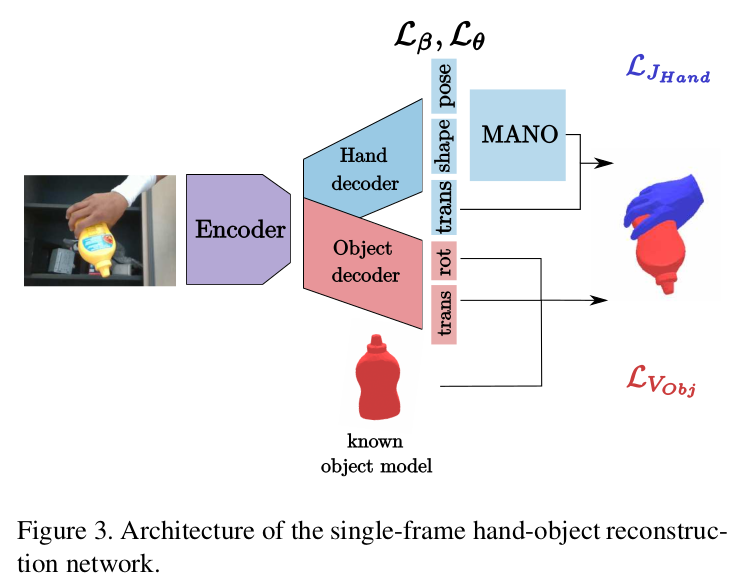
We apply the loss introduced in Sec. 3.1 to 3D hand-object reconstructions obtained independently for each frame. These per-frame estimates are obtained with a single forward pass through a deep neural network, whose architecture is shown in Fig. 3. In the spirit of [3, 12], our network takes as input a single RGB image and outputs MANO [38] pose and shape parameters. However, differently from [12], we assume that a 3D model of the object is given, and we regress its 6D pose by adding a second head to our network (see again Fig. 3). We employ as backbone a simple ResNet-18 [13], which is computationally very efficient (see Sec. 4). We use the base network model as the image encoder and select the last layer before the classifier to produce our image features. We then regress hand and object parameters from these features through 2 dense layers with ReLU non-linearities.
- 논문에서는 각 프레임에 대해 독립적으로 얻은 3D hand-object reconstruction을 위해 Section 3.1. 에서 소기한 loss를 적용한다. 이러한 프레임 마다의 추정치는 neural network를 통한 single forward pass로 얻어지며, 아키텍쳐는 Fig. 3과 같다. 이 네트워크는 single RGB image를 input으로 받아 MANO pose, shape parameter를 출력한다. 이전 논문과 달리 object 3D model이 제공된다고 가정하고 네트워크에 known object model을 추가하여 6D pose를 regression한다. Backbone으로는 ResNet-18을 사용한다. Base network model을 image encoder로 사용하고 image feature를 생성한다. 그런 다음 ReLU와 함께 2-dense layer를 통해 hand, object parameter를 regression한다.
Hand-object global pose estimation.
We formulate the hand-object global pose estimation problem in the camera coordinate system and aim to find precise absolute 3D positions of hands and objects. In our images, hand-object interactions are usually captured at a short distance from the camera. Namely, in order to estimate hand and object translation, we regress a focal-normalized depth offset and a 2D translation vector , defined in pixel space.
- 저자는 카메라 좌표계에서 hand-object global pose estimation 문제를 공식화하고 hand, object의 정확한 absolute 3D position을 찾는 것을 목표로 한다. 사용되는 이미지에서 hand-object interaction은 일반적으로 카메라로부터 짧은 거리에서 캡처된다. 따라서, 손과 물체의 translation을 추정하기 위해 픽셀 공간에서 정의된 focal-normalized depth offset 와 2D translation vector 를 regression한다.
We compute as
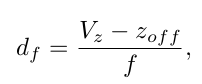
where is the distance between mesh vertex and camera center along the z-axis, f is the camera focal length, and is empirically set to 40cm. and represent the translation, in pixels, of the object (or hand) origin, projected on the image space, with respect to the image center. Note that we regress and for both the hand and the object, separately. Given the estimated and , and the camera intrinsics parameters, we can easily derive the object (hand) global translation in 3D. For the global rotation, we adopt the axis-angle representation. Following [18, 22, 30], the rotation for object and hand is predicted in the object-centered coordinate system.
- 여기서 는 z축을 따라 mesh vertex와 camera center 사이의 거리이고, f는 카메라 focal length, 는 경험적으로 40cm로 설정되어 있다. 와 는 image center에 대해 image space에 projection된 object 또는 hand 원점의 translation을 픽셀로 나타낸다. Hand, Object 모두에 대해 별도로 와 를 regression한다. 추정된 and 및 camera instrinsic parameter가 주어지면 3D에서 object (hand)의 global translation을 쉽게 유도할 수 있다. global rotation의 경우 axis-angle representation을 채택한다. 그리고 object-center coordinate system에서 object와 hand의 rotation이 예측된다.
Hand articulated pose and shape estimation.
We obtain hand 3D reconstructions by predicting MANO pose and shape parameters. For the pose, similarly to [3, 12], we predict the principal componant analysis (PCA) coefficients of the low-dimensional hand pose space provided in [38]. For the shape, we predict the MANO shape parameters, which control identity-specific characteristics such as skeleton bone length. Overall, we predict 15 pose coefficients and 10 shape parameters.
- 저자는 MANO pose 및 shape parameter를 예측하여 hand 3D reconstruction을 얻는데, pose의 경우 PCA coefficients, shape의 경우는 bone length와 같은 ID별 특성을 제어하는 MANO shape parameter이다. Pose coefficients는 15-dim, shape parameter는 10-dim이다.
Regularization losses.
We find it effective to regularize both hand pose and shape by applying penalization as in [3]. prevents unnatural joint rotations, while prevents extreme shape deformations, which can result in irregular and unrealistic hand meshes.
- 추가적으로 penalty를 hand pose와 shape에 적용하는 것이 효과적이다. 는 부자연스러운 joint rotation을 막고, 는 불규칙적이고 비현실적인 hand mesh를 초래할 수 있는 극단적인 모양 변형을 방지한다.
Skeleton adaptation.
Hand skeleton models can vary substantially between datasets, resulting in inconsistencies in the definition of joint locations. Skeleton mismatches may force unnatural deformations of the hand model. To account for these differences, we replace the fixed MANO joint regressor with a skeleton adaptation layer which regresses joint locations from vertex positions. We keep the tips of the fingers and the wrist joint fixed to the original locations, and learn a dataset-specific mapping for the other joints at training time.
- Hand skeleton model은 datasets 마다 크게 다를 수 있으므로 joint location 정의가 일관되지 않는다. Skeleton의 mismatch는 hand model이 부자연스럽게 변형될 수 있다. 이러한 차이를 설명하기 위해 fixed MANO joint regressor를 vertex position으로 부터 joint location을 regression하는 skeleton adaptation layer로 교체한다. 손가락 끝과 손목 joint를 original location에 고정하고 학습시에 다른 joint에 대한 dataset-specific mapping을 학습한다.
Reconstruction losses.
In total, we predict 6 parameters for hand-object rotation and translation and 25 MANO parameters, which result in a total of 37 regressed parameters. We then apply the predicted transformations to the reference hand and object models and further produce the 3D joint locations of the MANO hand model, which are output by MANO in addition to the hand vertex locations. We define our supervision on hand joint positions, , as well as on 3D object vertices, . Both losses are defined as errors. Our final loss is a weighted sum of the reconstruction and regularization terms:
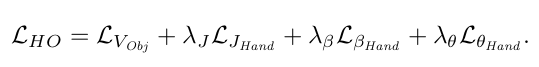
- 총 6개의 hand-object rotation, translation parameter와 25개의 MANO parameter를 예측하여 총 37개의 regression parameters를 생성한다. 그런 다음 예측된 변환을 reference hand와 object model에 적용하여 MANO hand model의 3D joint location을 생성한다. 저자는 hand joint position과 3D object vertex에 대한 supervision을 loss로 정의한다. 최종 loss는 regularization 및 reconstruction term의 weighted sum이다.
- Object Vertex error + hand 3D joint error (transformation을 hand, object에 적용 후 최종적인 Hand mesh로 부터 joint와 GT와의 비교) + mano parameter regularization
4. Evaluation
4.1. Datasets
FPHA (3D hand pose, 6D object pose, hand joint location에 대한 GT 있음), HO-3D (hand, manipulated object에 대한 3D pose anntation)
4.2. Evaluation Metrics
Mean 3D errors ⇒ 3D hand joint (21개) error, Object는 (FPHAB : average vertex distance , HO-3D : bounding box corner)
Mean 2D errors
4.3. Experimental Results
Single-frame hand-object reconstruction.

- [43] → H+O 논문이다. object error 성능이 더 좋고, 본 논문은 keypoint position을 regression하지 않고 미분불가능한 post-processing step이 필요없다.
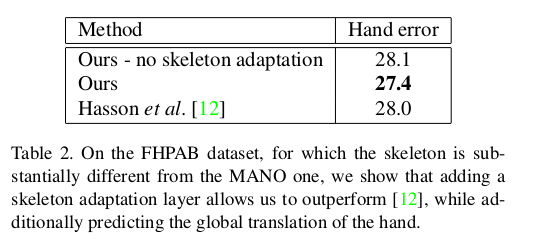
- FHPAB datasets은 골격이 MANO와 실질적으로 달라 skeleton adaptive layer를 추가하면 성능이 좋아지고, 추가적으로 모델이 camera space에서의 hand에 대해 global position을 추정한다.
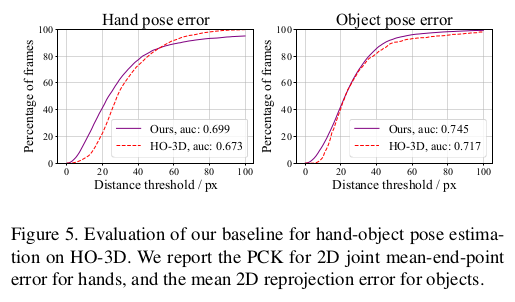
- HO-3D datasets에 대한 hand-object pose estimation 결과 HO-3D에서 제시한 network보다 성능이 좋다.
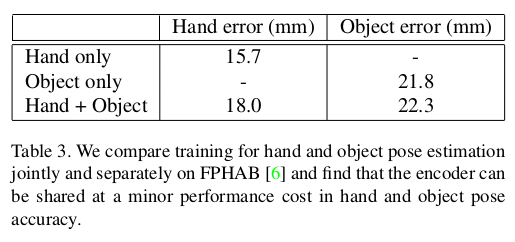
- 하나만을 학습할 때 보다 두 개에 대해 동시에 학습할 때 성능의 떨어짐이 발생하는데, 논문의 모델은 이 성능 비용이 작다.
Photometric supervision on video.
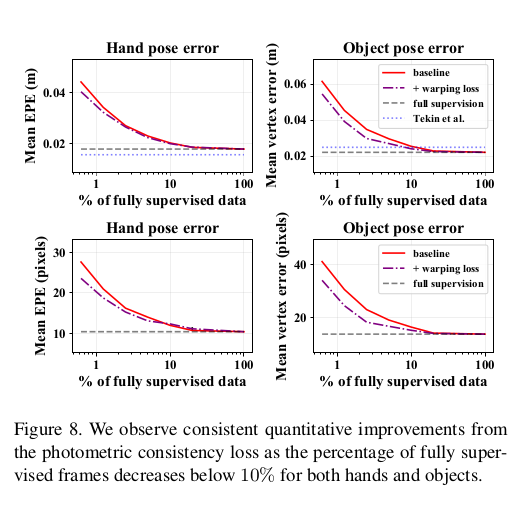
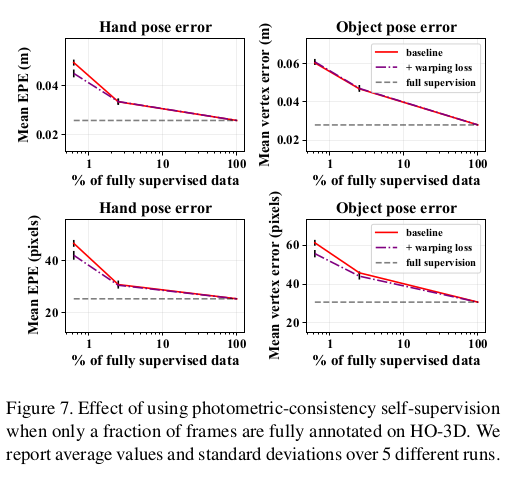
- Fig. 8은 FPHAB, Fig. 7은 HO-3D에서의 결과인데, 여기서 보면 모델이 FPHA에서는 프레임의 20%만 annotation이 있으면 fully supervision 방식으로 학습된 성능에 도달할 수 있음을 관찰했다. HO-3D의 경우에는 baseline과 처음에는 차이가 있다가 어느정도 지나면 같아짐.

- FPHAB full dataset에 학습하였을 때, reconstruction error가 가장 낮았다. supervision의 비율을 낮췄을때는 photometric consistency로 좋은 qualitative results를 얻을 수 있었다. 오른쪽은 잘 안된 case인데, 이는 occlusion이나 motion blur가 있을 때 발생한다.

- HO-3D에 대한 qualitative results이다. 질적으로 개선되었음을 볼 수 있다.
- 추가적으로, 논문의 방법은 photometric consistency의 가정이 위반될 때 잘 안되는데, 이는 예를 들어 빠른 움직임이나 조명 변화의 경우에 발생한다.

- 그러나 이 방법이 photometric consistency 가설이 유지되는 한 기준 frame과 target frame 사이에 큰 움직임이 발생하는 경우 의미있는 supervision을 제공할 가능성이 있다. 대부분의 경우 초기 포즈가 합리적으로 추정되므로 유익한 gradient를 제공할 수 있음을 관찰했고, 초기 예측이 정확하지 않더고 reference frame과 관련하여 큰 움직임이 있는 경우에도 포즈 추정을 개선할 수 있다. 이에 대한 예이다.
5. Conclusion
In this paper, we propose a new method for dense 3D reconstruction of hands and objects from monocular color images. We further present a sparsely supervised learning approach leveraging photo-consistency between sparsely supervised frames. We demonstrated that our approach achieves high accuracy for hand and object pose estimation and successfully leverages similarities between sparsely annotated and unannotated neighboring frames to provide additional supervision. Future work will explore additional self-supervised 3D interpenetration and scene interaction constraints for hand-object reconstruction.
- 이 논문에서 저자는 single RGB image로 부터 hand, object의 dense 3D reconstruction을 위한 새로운 method를 제안한다. 또한 sparse하게 supervison이 있는 frame 사이의 photometric consistency를 활용하는 sparse supervised learning approach를 제시한다. 논문에서는 이러한 접근 방식이 hand-object pose estimation에 대한 높은 정확도를 달성하고 추가적인 supervision을 제공하기 위해 sparse하게 annotation이 있는 인접 프레임과 annotation이 없는 이웃 프레임 간의 유사성을 성공적으로 활용한다는 것을 보여주었다. Future work로는 hand-object reconstruction을 위한 추가적인 self-supervised 3D interpenetration과 scene interaction에 대한 constraint을 제시하였다.
Uploaded by N2T
'Paper Summary' 카테고리의 다른 글
| ContactOpt: Optimizing Contact to Improve Grasps, CVPR’21 (0) | 2023.07.21 |
|---|---|
| SampleNet: Differentiable Point Cloud Sampling, CVPR’20 (0) | 2023.07.21 |
| Offline RL Without Off-Policy Evaluation, NIPS’21 (0) | 2023.07.21 |
| Revisiting Skeleton-based Action Recognition, CVPR’22 (0) | 2023.07.21 |
| DG-STGCN: Dynamic Spatial-Temporal Modeling for Skeleton-based Action Recognition, ACM MM’22 (0) | 2023.07.21 |