Abstract
Most prior approaches to offline reinforcement learning (RL) have taken an iterative actor-critic approach involving off-policy evaluation. In this paper we show that simply doing one step of constrained/regularized policy improvement using an on-policy Q estimate of the behavior policy performs surprisingly well. This one-step algorithm beats the previously reported results of iterative algorithms on a large portion of the D4RL benchmark. The one-step baseline achieves this strong performance while being notably simpler and more robust to hyper-parameters than previously proposed iterative algorithms.
- 대부분의 offline RL에 대한 접근 방식은 off-policy evaluation을 포함하는 actor-critic 접근 방식을 사용했다. 이 논문에서는 behavior policy에 on-policy Q estimate을 사용하여 one step만 constrained / regularized policy improvement을 수행하는 것이 성능을 높였다는 것을 보여준다. 이 one-step 알고리즘은 D4RL benchmark에서 이전에 보고된 iterative 알고리즘의 결과를 능가한다.
We argue that the relatively poor performance of iterative approaches is a result of the high variance inherent in doing off-policy evaluation and magnified by the repeated optimization of policies against those estimates. In addition, we hypothesize that the strong performance of the one-step algorithm is due to a combination of favorable structure in the environment and behavior policy.
- 논문에서는 iterative approach의 상대적으로 낮은 성능이 off-policy evaluation을 할 때 내재되어있는 high variance로 부터의 결과이고 이러한 추정치에 대해 policy를 반복적으로 optimization하는 것으로부터 확대된다고 주장한다. 또한, one-step algorithm의 강력한 성능은 환경의 유리한 구조와 behavior policy의 조합 덕분이라고 가정한다.
Review
이전에 수행된 대부분의 Offline RL에서는 off-policy evaluation과 관련된 반복적인 Actor-critic 기법 활용했다. 이 논문에서는 behavior policy의 on-policy Q estimate을 사용해서 제한된/정규화된 policy improvement를 단순히 한 번만 수행해도 잘 동작하는 것을 확인했다. 이 one-step baseline이 이전에 발표되었던 논문에 비하면 눈에 띌만큼 간단하면서도 hyper-parameter에 대해서 robust한 결과를 얻을 수 있었다. 이전의 iterative 방법들이 상대적으로 낮은 성능을 띄는 이유는 off-policy evaluation을 하면서 high variance가 상속되고, 이 estimate에 대해서 policy에 대한 최적화 작업이 반복되면서 점점 커지기 때문이었다.
1. Introduction
An important step towards effective real-world RL is to improve sample efficiency. One avenue towards this goal is offline RL (also known as batch RL) where we attempt to learn a new policy from data collected by some other behavior policy without interacting with the environment.
- 효율적인 real-world RL을 향한 중요한 단계는 sample efficiency를 개선하는 것이다. 이 목표를 향한 한 가지 방법은 환경과 상호 작용하지 않고 다른 행동 정책에서 수집한 데이터에서 새로운 정책을 배우려고 시도하는 오프라인 RL(배치 RL이라고도 함)이다.
In this paper, we challenge the dominant paradigm in the deep offline RL literature that primarily relies on actor-critic style algorithms that alternate between policy evaluation and policy improvement. All these algorithms rely heavily on off-policy evaluation to learn the critic. Instead, we find that a simple baseline which only performs one step of policy improvement using the behavior Q function often outperforms the more complicated iterative algorithms. Explicitly, we find that our one-step algorithm beats prior results of iterative algorithms on most of the gym-mujoco and Adroit tasks in the the D4RL benchmark suite.
- 본 논문에서 저자는 policy evaluation과 policy improvement 사이를 번갈아가며 사용하는 actor-critic style algorithm에 주로 의존하는 deep offline RL의 지배적인 패러다임에 도전한다. 이러한 모든 알고리즘은 critic을 학습하기 위해 off-policy evaluation에 크게 의존한다. 대신 behavior Q function을 사용하여 policy improvement의 one step만 수행하는 단순한 baseline이 종종 더 복잡한 iterative algorithm보다 성능이 우수하다는 것을 발견했다. 명시적으로, 저자는 D4RL 벤치마크에서 대부분의 gym-mujoco 및 Adroit 작업에서 논문에서 제시한 one-step algorithm이 iterative algorithm의 이전 결과를 능가한다는 것을 발견했다.
We then dive deeper to understand why such a simple baseline is effective. First, we examine what goes wrong for the iterative algorithms. When these algorithms struggle, it is often due to poor off-policy evaluation leading to inaccurate Q values. We attribute this to two causes: (1) distribution shift between the behavior policy and the policy to be evaluated, and (2) iterative error exploitation whereby policy optimization introduces bias and dynamic programming propagates this bias across the state space. We show that empirically both issues exist in the benchmark tasks and that one way to avoid these issues is to simply avoid off-policy evaluation entirely.
- 그런 다음 이러한 간단한 baseline이 효과적인 이유를 더 깊이 이해한다. 먼저, iterative algorithm에서 무엇이 잘못되었는지 조사한다. 이러한 알고리즘이 어려움을 겪을 때 종종 잘못된 off-policy evaluation이 부정확한 Q값을 이끈다. 저자는 2가지 원인을 제시하는데 (1) behavior policy와 평가할 policy 사이의 distribution shift (2) policy optimization이 bias를 도입하고 dynamic programming이 이 bias를 state space 전체에 전파하는 iterative error exploitation 이다. 논문에서는 경험적으로 두 가지 문제가 benchmark task에 존재하며 이러한 문제를 피하는 한 가지 방법은 단순히 off-policy evaluation을 완전히 피하는 것임을 보여준다.
In the final section we provide some guidance about when iterative algorithms can perform better than the simple one-step baseline. Namely, when the dataset is large and behavior policy has good coverage of the state-action space, then off-policy evaluation can succeed and iterative algorithms can be effective. In contrast, if the behavior policy is already fairly good, but as a result does not have full coverage, then one-step algorithms are often preferable.
- 마지막 섹션에서는 iterative algorithm이 단순한 one-step baseline보다 더 잘 수행될 수 있는 경우에 대한 몇 가지 지침을 제공한다. 즉, dataset이 크고 policy behavior이 state-action space를 잘 커버할 때 off-policy evaluation이 성공할 수 있고 iterative algorithm이 효과적일 수 있다. 대조적으로, behavior policy가 이미 상당히 훌륭하지만 결과적으로 전체 적용 범위가 없는 경우 one-step algorithm이 선호되는 경우가 많다.
Contribution
A demonstration that a simple baseline of one step of policy improvement outperforms more complicated iterative algorithms on a broad set of offline RL problems.
- one step policy improvement의 simple baseline이 광범위한 offline RL 문제에서 더 복잡한 iterative algorithm보다 성능이 우수함을 보여준다.
An examination of failure modes of off-policy evaluation in iterative offline RL algorithms.
- Iterative offline RL algorithm에서 off-policy evaluation의 실패 케이스를 조사하였다.
A description of when one-step algorithms are likely to outperform iterative approaches.
- One step algorithm이 iterative 방식보다 성능이 좋을 가능성이 있는 경우에 대해 설명하였다.
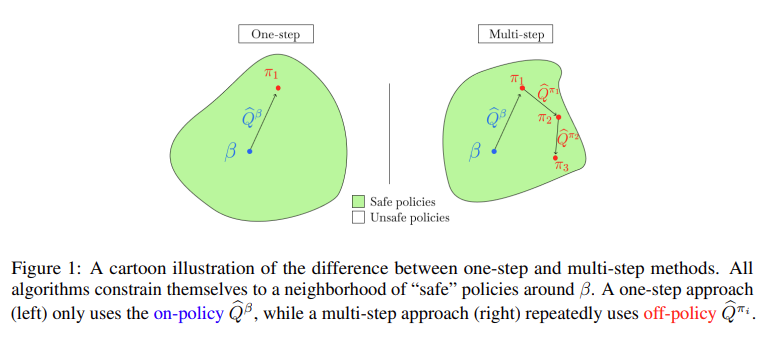
2. Setting and notation
We will consider an offline RL setup as follows. Let be a discounted infinite horizon MDP. In this work we focus on applications in continuous control, so we will generally assume that both and are continuous and bounded. We consider the offline setting where rather than interacting with , we only have access to a dataset of tuples of collected by some behavior policy with initial state distribution . Let be the expected reward. Define the state-action value function for any policy π by . The objective is to maximize the expected return of the learned policy:
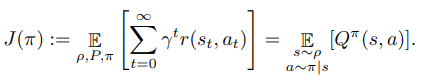
Following Fu et al. [2020] and others in this line of work, we allow access to the environment to tune a small (< 10) set of hyperparameters. See Paine et al. [2020] for a discussion of the active area of research on hyperparameter tuning for offline RL. We also discuss this further in Appendix C.
- 본 논문에서 은 discounted infinite horizon MDP 이다. 이 작업에서는 continuous control에서 application에 중점을 두므로 일반적으로 state와 action은 모두 연속적이고 bounded하다고 가정한다. 또한 MDP와 상호 작용하는 대신 초기 state distribution과 일부 behavior policy에 의해 수집된 의 tuples로 이루어진 dataset에만 엑세스할 수 있는 offline setting을 고려한다. 여기서 r은 expected reward이다. 어느 policy π에 대해서 state-action value function은 Q이다. 여기서의 목적은 학습된 policy에 대해 expected return J를 maximize하는 것이다.
3. Related work
Iterative algorithms
Most prior work on deep offline RL consists of iterative actor-critic algorithms. The primary innovation of each paper is to propose a different mechanism to ensure that the learned policy does not stray too far from the data generated by the behavior policy. Broadly, we group these methods into three camps: policy constraints/regularization, modifications of imitation learning, and Q regularization:
- Deep offline RL에 대한 대부분의 이전 작업은 iterative actor-critic algorithm으로 구성된다. 각 논문의 주요 혁신은 학습된 policy가 behavior policy에 의해 생성된 데이터에서 너무 멀리 벗어나지 않도록 다른 메커니즘을 제안하는 것이다. 일반적으로 이러한 방법을 policy constraints/regularization, modification of imitation learning 및 Q regularization 3가지의 group으로 나눈다.
- The majority of prior work acts directly on the policy. Some authors have proposed explicit constraints on the learned policy to only select actions where (s, a) has sufficient support under the data generating distribution [Fujimoto et al., 2018a, 2019, Laroche et al., 2019]. Another proposal is to regularize the learned policy towards the behavior policy [Wu et al., 2019] usually either with a KL divergence [Jaques et al., 2019] or MMD [Kumar et al., 2019]. This is a very straighforward way to stay close to the behavior with a hyperparameter that determines just how close. All of these algorithms are iterative and rely on off-policy evaluation.
- 이전 작업의 대부분은 policy에 직접적으로 작용한다. 일부 저자는 데이터 생성 분포에서 (s, a)가 충분한 지원을 갖는 경우에만 action을 선택하기 위해 학습된 policy에 대한 명시적인 제약을 제안했다. 또 다른 제안은 학습된 policy를 behavior policy에 대해 일반적으로 KL divergence 또는 MMD로 정규화하는 것이다. 이것은 얼마나 가까운지를 결정하는 하이퍼파라미터를 사용하여 behavior에 가깝게 유지하는 매우 간단한 방법이다. 이러한 알고리즘은 모두 iterative하며 off-policy evaluation에 의존한다.
- Siegel et al. [2020], Wang et al. [2020b], Chen et al. [2020] all use algorithms that filter out datapoints with low Q values and then perform imitation learning. Wang et al. [2018], Peng et al. [2019] use a weighted imitation learning algorithm where the weights are determined by exponentiated Q values. These algorithms are iterative.
- 위의 세 논문 모두 낮은 Q value를 가진 data point를 필터링한 다음 imitation learning을 수행하는 알고리즘을 사용한다. 그리고 위 두 논문은 weight가 Q 값에 의해 결정되는 weighted imitation learning algorithm을 사용한다. 이러한 algorithm은 iterative하다.
- Another way to prevent the learned policy from choosing unknown actions is to incorporate some form of regularization to encourage staying near the behavior and being pessimistic about unknown state, action pairs [Wu et al., 2019, Nachum et al., 2019, Kumar et al., 2020, Kostrikov et al., 2021, Gulcehre et al., 2021]. However, being able to properly quantify uncertainty about unknown states is notoriously difficult when dealing with neural network value functions [Buckman et al., 2020].
- 학습된 policy가 알려지지 않은 action을 선택하는 것을 방지하는 또 다른 방법은 action 근처에 머물로 알려지지 않은 state, action pair에 대해 비관적이 되도록하기 위해 일종의 정규화를 통합시키는 것이다. 그러나 미지의 상태에 대한 불확실성을 적절하게 정량화하는 것은 neural network value function을 다룰 때 매우 어렵기로 악명이 높다.
One-step algorithms
Some recent work has also noted that optimizing policies based on the behavior value function can perform surprisingly well. As we do, Goo and Niekum [2020] studies the continuous control tasks from the D4RL benchmark, but they examine a complicated algorithm involving ensembles, distributional Q functions, and a novel regularization technique. In contrast, we analyze a substantially simpler algorithm and get better performance on the D4RL tasks. Gulcehre et al. [2021] studies the discrete action setting and finds that a one-step algorithm (which they call “behavior value estimation”) outperforms prior work on Atari games and other discrete action tasks from the RL Unplugged benchmark [Gulcehre et al., 2020]. They also introduce a novel regularizer for the evaluation step. In contrast, we consider the continuous control setting. This is a substantial difference in setting since continuous control requires actor-critic algorithms with parametric policies while in the discrete setting the policy improvement step can be computed exactly from the Q function. Moreover, while Gulcehre et al. [2021] attribute the poor performance of iterative algorithms to “overestimation”, we define and separate the issues of distribution shift and iterative error exploitation which can combine to cause overestimation. This separation helps to expose the difference between the fundamental limits of off-policy evaluation from the specific problems induced by iterative algorithms, and will hopefully be a useful distinction to inspire future work.
- 일부 최근 연구에서는 behavior value function에 기반한 policy optimization이 놀라울 정도로 잘 수행될 수 있다고 언급했다. 본 논문과 마찬가지로 Goo, Niekum은 D4RL 벤치마크에서 continuous control task를 연구하지만 ensemble, distributional Q function, novel regularization technique을 포함하는 복잡한 알고리즘을 조사한다. 대조적으로 본 논문에서는 훨씬 더 간단한 알고리즘을 분석하고 D4RL 작업에서 더 나은 성능을 얻는다. Gulcehre et al. 에서는 discrete action setting을 연구하고 one-step algorithm(논문에서는 이를 behavior value estimation이라고 함)이 RL Unplugged 벤치마크의 Atari game 및 기타 discrete action task에 대한 이전 작업보다 성능이 우수함을 발견했다. 또한 이들은 평가 단계를 위한 새로운 regularizer를 도입한다. 대조적으로, 본 논문에서는 continuous control setting을 고려한다. Continuous control에서는 parametric policy가 있는 actor-critic algorithm이 필요하지만 discrete setting에서는 policy improvement step이 Q function에서 정확하게 계싼될 수 있기 때문에 이는 설정에서 상당한 차이이다. 또한 Gulcehre et al. [2021] 에서의 iterative algorithm에 대한 poor performance는 “overestimation”에 기인하며, 저자는 overestimation을 유발하기 위해 결합될 수 있는 distribution shift 및 iterative error exploitation 문제를 정의하고 분리한다. 이러한 분리는 iterative algorithm에 의해 유발된 특정 문제로 부터의 off-policy evaluation에 대한 근본적인 한계 간의 차이를 노출하는 데 도움이 되며 향후 작업에 영감을 주는 유용한 구별이 되기를 바란다.
4. Defining the algorithms
In this section we provide a unified algorithmic template for model-free offline RL algorithms as offline approximate modified policy iteration. We show how this template captures our one-step algorithm as well as a multi-step policy iteration algorithm and an iterative actor-critic algorithm. Then any choice of policy evaluation and policy improvement operators can be used to define one step, multi-step, and iterative algorithms.
- 이 섹션에서는 model-free offline RL algorithm을 위한 통합 알고리즘 템플릿을 offline approximate modified policy iteration으로 제공한다. 이 템플릿이 어떻게 저자의 one-step algorithm과 multi-step policy iteration algorithm 및 iterative actor-critic algorithm을 캡처하는지 보여준다. 그런 다음 선택한 policy evaluation 및 policy improvement operator를 사용하여 one step, multi-step, iterative algorithm을 정의할 수 있다.
4.1. Algorithmic template

We consider a generic offline approximate modified policy iteration (OAMPI) scheme, shown in Algorithm 1 (and based off of Puterman and Shin [1978], Scherrer et al. [2012]). Essentially the algorithm alternates between two steps. First, there is a policy evaluation step where we estimate the Q function of the current policy by using only the dataset . Implementations also often use the prior Q estimate to warm-start the approximation process. Second, there is a policy improvement step. This step takes in the estimated Q function , the estimated behavior , and the dataset and produces a new policy . Again an algorithm may use to warm-start the optimization. Moreover, we expect this improvement step to be regularized or constrained to ensure that remains in the support of β and .
- 저자는 Algorithm 1에 표시된 generic offline approximate modified policy iteration (OAMPI) 방식을 고려한다. 기본적으로 알고리즘은 두 단계를 번갈아 수행한다. 먼저 데이터셋만 사용하여 현재 policy 에 대해 Q function을 로 추정하여 policy evaluation을 하는 단계가 있다. 구현에서는 종종 prior Q estimate 를 사용하여 approximation process를 warm-start한다. 둘째, policy improvement step이다. 이 step은 추정된 Q function, behavior, dataset을 통해 새로운 policy를 제공한다. 다시 알고리즘은 최적화를 warm-start하기 위해 current policy를 사용할 수 있다. 게다가, 이러한 improvement step이 가 β and 의 지원을 유지하도록 보장하기 위해 정규화되거나 제한될 것으로 기대한다.
One-step
The simplest algorithm sets the number of iterations K = 1. We learn by maximum likelihood and train the policy evaluation step to estimate . Then we use any one of the policy improvement operators discussed below to learn . Importantly, this algorithm completely avoids off-policy evaluation.
- 가장 간단한 알고리즘은 반복 횟수 K = 1을 설정한다. 을 maximum likelihood로 학습하고 policy evaluation step을 학습시켜 를 추정하게 한다. 그리고 나서 아래에 설명된 policy improvement operator 중 하나를 사용하여 를 학습한다. 중요하게, 이 알고리즘은 off-policy evaluation을 완전히 피한다.
Multi-step
The multi-step algorithm now sets K > 1. The evaluation operator must evaluate off-policy since is collected by β, but evaluation steps for K ≥ 2 require evaluating policies . Each iteration is trained to convergence in both the estimation and improvement steps.
- multi-step algorithm은 K > 1을 설정한다. evaluation operator는 off-policy를 평가해야하는데 이는 dataset이 behavior에 의해 수집되기 때문이다. 그러나 K ≥ 2 의 evaluation step은 의 policy를 평가해야한다. 각 iteration estimation 및 improvement step에서 수렴하도록 학습된다.
Iterative actor-critic
An actor critic approach looks somewhat like the multi-step algorithm, but does not attempt to train to convergence at each iteration and uses a much larger K. Here each iteration consists of one gradient step to update the Q estimate and one gradient step to improve the policy. Since all of the evaluation and improvement operators that we consider are gradient-based, this algorithm can adapt the same evaluation and improvement operators used by the multi-step algorithm.
- actor-critic 방식은 multi-step algorithm과 다소 유사하지만 각 iteration에서 수렴하도록 학습하지 않고 훨씬 더 큰 K를 사용한다. 여기서 각 iteration은 Q estimate을 업데이트하기 위한 하나의 gradient step과 policy improvement를 위한 하나의 gradient step으로 구성된다. 논문에서 고려하는 모든 evaluation, improvement operator는 gradient-based 이므로 multi-step algorithm에서 사용하는 것과 동일판 evaluation, improvement operator를 적용할 수 있다.
4.2. Policy evaluation operator
Following prior work on continuous state and action problems, we always evaluate by simple fitted Q evaluation. In practice this is optimized by TD-style learning with the use of a target network as in DDPG. We do not use any double Q learning or Q ensembles. For the one-step and multi-step algorithms we train the evaluation procedure to convergence on each iteration and for the iterative algorithm each iteration takes a single stochastic gradient step. It is an interesting direction for future work to consider other operators that use things like importance weighting.
- Continuous state, action 문제에 대한 prior work에 이어 논문에서는 항상 simple fitted Q evaluation으로 평가한다. 실제로 이것은 DDPG에서와 같이 target network를 사용하여 TD-style 학습에 의해 최적화 된다. 저자는 이중 Q learning이나 Q ensemble을 사용하지 않는다. one-step , multi-step algorithm의 경우 각 iteration에서 수렴하도록 평가 절차를 학습하고 iterative algorithm의 경우 각 iteration은 stochastic gradient step을 취한다. importance weight같은 것을 사용하는 다른 operator를 고려하는 것은 future work에 대한 흥미로운 방향이다.
4.3. Policy improvement operators
To instantiate the template, we also need to choose a specific policy improvement operator . Each operator has a hyper-parameter controlling deviation from the behavior policy.
- 템플릿을 인스턴스화하려면 특정 policy improvement operator 도 선택해야 한다. 각 연산자는 behavior policy의 deviation을 제어하는 hyper-parameter를 가지고 있다
Behavior cloning
The simplest baseline worth including is to just return as the new policy . Any policy improvement operator ought to perform at least as well as this baseline.
- 포함할 가치가 있는 가장 간단한 baseline은 을 new policy 로 반환하는 것이다. 모든 policy improvement operator는 최소한 이 baseline만큼 수행해야 한다.
Constrained policy updates
Algorithms like BCQ [Fujimoto et al., 2018a] and SPIBB constrain the policy updates to be within the support of the data/behavior. In favor of simplicity, we implement a simplified version of the BCQ algorithm that removes the “perturbation network” which we call Easy BCQ. We define a new policy by drawing samples from and then executing the one with the highest value according to . Explicitly:
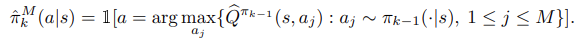
- BCQ 및 SPIBB와 같은 알고리즘은 policy update가 data/behavior의 support 범위 내에 있도록 제한합니다. 단순성을 위해 EasyBCQ라고 하는 “perturbation network”를 제거하는 BCQ 알고리즘의 단순화된 버전을 구현한다. 에서 sample을 가져온 다음 에서 가장 높은 value를 가진 policy 를 실행하여 새로운 policy 를 정의한다.
Regularized policy updates
Another common idea proposed in the literature is to regularize towards the behavior policy. For a general divergence D we can define an algorithm that maximizes a regularized objective:
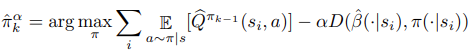
- 문헌에서 제안된 또 다른 일반적인 아이디어는 behavior policy로 regularize 하는 것이다. general divergence D에 대해 정규화된 목표를 최대화하는 알고리즘을 정의할 수 있다.
In practice, we will use reverse KL divergence, i.e. . To compute the reverse KL, we draw samples from and use the density estimate to compute the divergence. Intuitively, this regularization forces π to remain within the support of rather than incentivizing π to cover .
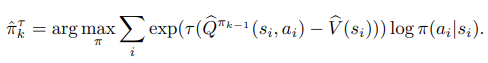
- 실제로, 논문에서는 reverse KL-divergence를 사용할 것이다. Reverse KL을 계산하기 위해 에서 샘플을 추출하고 density estimate 를 사용하여 divergence를 계산한다. 직관적으로, 이 정규화는 를 포함하도록 를 인센티브화하는 대신 가 의 지원 범위 내에 있도록 한다.
With these definitions, we can now move on to testing various combinations of algorithmic template (one-step, multi-step, or iterative) and improvement operator (Easy BCQ, reverse KL regularization, or exponentially weighted imitation).
- 이러한 정의를 통해 이제 알고리즘 템플릿 (one-step, multi-step or iterative) 및 improvement operator의 다양한 조합을 테스트할 수 있다.
Uploaded by N2T