논문 링크 : https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123570035.pdf
Abstract
We present a method that infers spatial arrangements and shapes of humans and objects in a globally consistent 3D scene, all from a single image in-the-wild captured in an uncontrolled environment. Notably, our method runs on datasets without any scene- or object level 3D supervision. Our key insight is that considering humans and objects jointly gives rise to “3D common sense” constraints that can be used to resolve ambiguity. In particular, we introduce a scale loss that learns the distribution of object size from data; an occlusion-aware silhouette re-projection loss to optimize object pose; and a human-object interaction loss to capture the spatial layout of objects with which humans interact. We empirically validate that our constraints dramatically reduce the space of likely 3D spatial configurations. We demonstrate our approach on challenging, in-the-wild images of humans interacting with large objects (such as bicycles, motorcycles, and surfboards) and handheld objects (such as laptops, tennis rackets, and skateboards).
- 저자는 uncontrolled 환경에서 캡쳐된 in-the-wild single image의 상황에서 globally consistent 3D scene에서 human-object 간의 spatial arrangement와 shape을 추론하는 방법을 제시한다. 특히, 제시한 방법이 scene 또는 object 수준의 3D supervision 없이 dataset에서 실행된다. 논문의 Key insight는 human-object를 동시에 고려하면 ambiguity를 해결하는 데 사용할 수 있는 “3D common sense”(상식) 라는 제약이 발생한다는 것이다. 특히, 데이터에서 object size의 distribution을 학습하는 scale loss를 도입한다.(object pose를 optimize하기 위한 occlusion-aware silhouette re-projection loss, human이 interact하는 object에 대한 spatial layout을 캡처하기 위한 human-object intearction loss) 저자는 제시한 constraints가 3D spatial configuration에 대한 space를 크게 줄인다는 것을 경험적으로 검증한다. 저자는 큰 물체(자전거, 오토바이, 서핑보드 등)와 휴대용 물체(노트북, 테니스라켓, 스케이트보드 등)와 interaction하는 human에 대한 in-the-wild image에서 제시한 방법을 보여준다.
1. Introduction
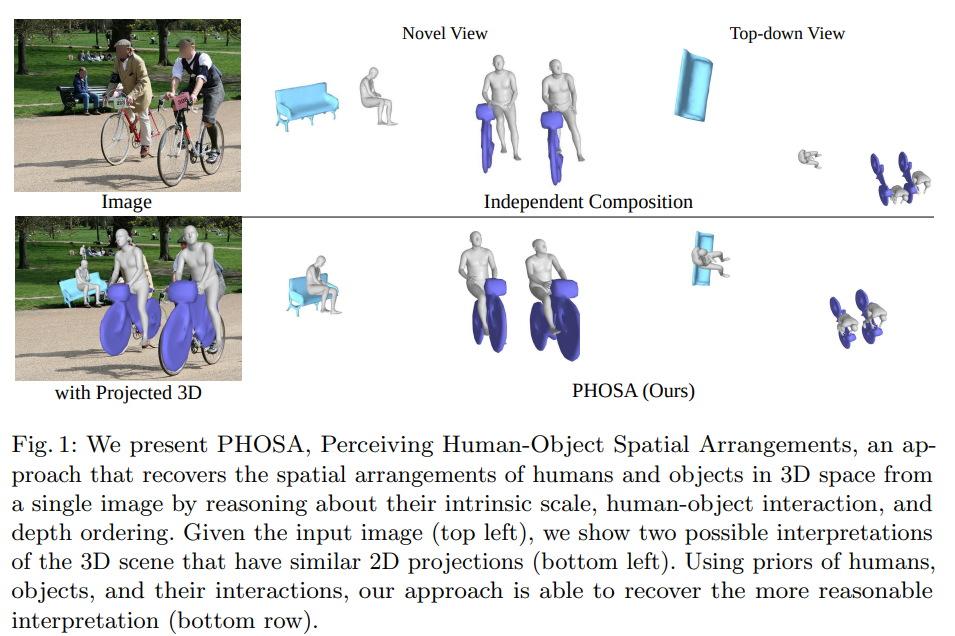
- PHOSA라는 방식은 single image로 부터 intrinsic scale, human-object interaction, depth ordering을 추론함으로써 3D space 상에서 human과 object에 대한 spatial arrangements를 복원하는 방법론이다. Input image가 주어지면, 저자는 2D projection과 비슷하게 3D scene에 대한 2가지 해석을 제시한다. (아래 왼쪽 2개). 그리고 human, object 그리고 interaction에 대한 prior의 사용은 더 reasonable한 interpretation을 복원할 수 있도록 한다. (아래 라인 전체)
There are three significant challenges to address.
First is that the problem is inherently ill-posed as multiple 3D configurations can result in the same 2D projection. It is attractive to make use of data-driven priors to resolve such ambiguities.
- 첫 번째는, multiple 3D configuration이 같은 2D projection을 초래할 수 있으므로 문제 자체가 본질적으로 ill-posed 된다는 것이다. 이러한 ambiguity를 해결하기 위해 data-driven priors를 사용하는 것이 좋다.
But we immediately run into the second challenge: obtaining training data with 3D supervision is notoriously challenging, particularly for entire 3D scenes captured in-the-wild. Our key insight is that considering humans and objects jointly gives rise to 3D scene constraints that reduce ambiguity. We make use of physical 3D constraints including a prior on the typical size of objects within a category. We also incorporate spatial constraints that encode typical modes of interactions with humans (e.g. humans typically interact with a bicycle by grabbing its handlebars).
- 두 번째 문제는 3D supervision에 대한 training data를 얻는것이 매우 어렵고, 이는 특히 in-the-wild에서 캡쳐된 전체 3D scene에 대해서 더 어렵다. 저자의 key insight는 human과 object를 동시에 고려하는 것이 ambiguity를 줄이는 3D scene constraint가 발생한다는 것이다. 저자는 category 내의 object의 일반적인 크기에 대한 prior를 포함하여 physical 3D constraints를 사용한다. 또한 human과의 일반적인 interaction mode를 encoding하는 spatial constraints를 통합한다. (ex ; 사람은 일반적으로 handlebars를 잡아 bicycle과 상호작용한다.)
Our final challenge is that while there exists numerous mature technologies supporting 3D understanding of humans (including shape models and keypoint detectors), the same tools do not exist for the collective space of all objects. In this paper, we take the first step toward building such tools by learning the natural size distributions of object categories without any supervision. Our underlying thesis, bourne out by experiment, is that contextual cues arising from holistic processing of human-object arrangements can still provide enough information to understand objects in 3D.
- 마지막 challenge는 shape model과 keypoint detector를 포함하여 인간에 대한 3D understanding을 지원하는 기술들이 있지만, 모든 object에 대한 collective space를 위한 동일한 tool이 없다는 것이다. 논문에서 저자는 supervision 없이 object category에 대한 natural size distribution을 학습함으로서 이러한 tool을 구축하기 위한 첫 번째 단계를 수행한다. 실험을 통해 밝혀진 논문의 기본 논제는 human-object arrangement의 holistic processing에서 발생하는 contextual cue가 여전히 3D에서 object를 이해하는데 충분한 정보를 제공할 수 있다는 것이다.

Image가 주어지면, 먼저 human과 object에 대한 instance를 detection한다. 그리고 각 사람에 대한 3D pose와 shape을 예측하는 것과, 각 object에 대한 3D pose를 segmentation mask에 optimization 시키는 것을 진행한다. 그리고 intrinsic scale을 사용해서 local coordinate frame의 각 3D instance를 world coordinate로 변환시킨다. Human-Object Spatial Arrangement optimization을 사용해 그림처럼 globally consistent output을 생성한다. 저자의 framework는 realistic human-object interaction을 캡쳐하고, depth ordering을 보존하면서 physical constraints를 준수하는 plausible한 reconstruction을 생성한다.
3. Method
3.1. Estimating 3D Humans
Detection algorithm을 통해 human bounding box가 주어지면, SMPL 3D shape과 pose parameter를 추정한다.([27] algorithm 사용해서) Human parameter는 pose, shape 각각 이다. 그리고 weak-perspective camera 는 mesh을 image coordinate에 projection 시킬 때 사용한다.
실제로 키가 크고 멀리 있는 사람과 키가 작고 가까이 있는 사람이 유사한 이미지 영역에 projection될 수 있기 떄문에 image에서 이를 안정적으로 estimation하는 것은 어렵다. 이러한 ambiguity를 해결하기 위해 estimate된 SMPL pose와 shape을 수정하고 world coordinate에서 human depth와 size를 변경하는 per human intrinsic scale parameter를 추가로 도입한다.
3.2. Estimating 3D Objects
We consider single or multiple exemplar mesh models for each object category, pre-selected based on the shape variation within each category. The mesh models are obtained from [1,2,38] and are pre-processed to have fewer faces (about 1000) to make optimization more efficient.
The 3D state of the jth object is represented as,
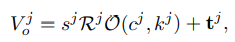
where O(, ) specifies the -th exemplar mesh for category . Note that the object category is provided by the object detection algorithm [24], and is automatically determined in our optimization framework (by selecting the exemplar that minimizes reprojection error).
- object의 3D state는 다음과 같다. 여기서 O는 category 에 있는 exemplar mesh이다. Object category는 object detection algorithm을 통해 찾고, 는 optimization framework를 통해서 자동적으로 결정된다.(reprojection error를 최소화 시키는 방식)
Our first goal is to estimate the 3D pose of each object independently. However, estimating 3D object pose in the wild is challenging because (1) there are no existing parametric 3D models for target objects; (2) 2D keypoint annotations or 3D pose annotations for objects in the wild images are rare; and (3) occlusions are common in cluttered scenes, particularly those with humans.
- 저자의 첫번 째 목표는 각 object들에 대해서 독립적으로 3D pose를 추정하는 것이다. 그러나, in the wild setting에서는 몇 가지 어려운 점이 있는데,
- Target object에 대한 parametric 3D model이 없다.
- In the wild image에서 object에 대한 2D keypoint annotation or 3D pose annotation이 적다.
- Occlusion이 scene에서 많이 일어난다. (특히 사람이랑)
We propose an optimization-based approach using a differentiable renderer [31] to fit the 3D object to instance masks from [24] in a manner that is robust to partial occlusions. We began with an pixel-wise L2 loss over rendered silhouettes S versus predicted masks M, but found that it ignored boundary details that were important for reliable pose estimation. We added a symmetric chamfer loss [14] which focuses on boundary alignment, but found it computationally prohibitive since it required recomputing a distance transform of S at each gradient iteration.
- 본 논문에서는 partial occlusion에 robust한 방식으로 instance mask에 3D object를 fit하기 위해 differentiable renderer를 사용하는 optimization-based approach를 제시한다. 저자는 rendering된 silhouettes S vs predicted mask M 사이의 pixel-wise L2 loss에서 시작했었는데, 이는 pose estimation에서 중요한 boundary detail을 무시한다는 것을 발견했다. 그리고 symmetric chamfer loss도 고려했는데, 이는 computiationally prohibitive하다는 것을 발견했다.
We found good results with L2 mask loss augmented with a one-way chamfer loss that computes the distance of each silhouette boundary pixel to the nearest mask boundary pixel, which requires computing a single distance transform once for the mask M. Given an no-occlusion indicator I (0 if pixel only corresponds to mask of different instance, 1 else), we write our loss as follows:
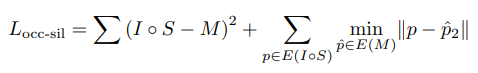
- 최종적으로, 각silhouette boundary pixel에서 nearest mask boundary pixel까지의 distance를 구하는 one-way chamfer loss로 augmented된 L2 mask loss로 좋은 결과를 얻었다. 여기서 loss는 mask M에 대해서 single distance transform을 한 번 계산하면 된다. no-occlusion indicator I가 주어지면, loss를 다음과 같이 사용한다. (pixel이 다른 instance의 mask에만 해당하는 경우 0, 그렇지 않으면 1)
where E(M) computes the edge map of mask M.
Note that this formulation can handle partial occlusions by object categories for which we do not have 3D models, as illustrated in Fig. 4.

We also add an offscreen penalty to avoid degenerate solutions when minimizing the chamfer loss. To estimate the 3D object pose, we minimize the occlusion-aware silhouette loss:
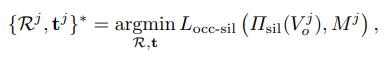
- 또한 chamfer loss를 minimize할 때 degenerate solution을 막기위해 offscreen penalty를 추가한다. 3D object pose를 추정하기 위해 occlusion-aware silhouette loss를 최소화한다.
where is the silhouette rendering of a 3D mesh model via a perspective camera with a fixed focal length (same as f in (1)) and is a 2D instance mask for the j-th object.
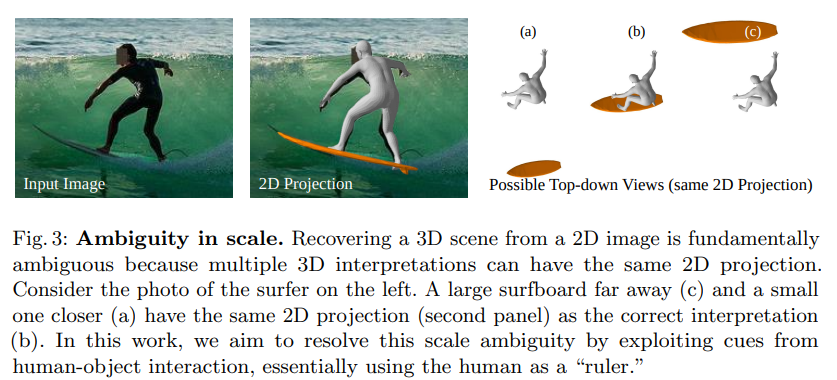
While this per-instance optimization provides a reasonable 3D pose estimate, the mask-based 3D object pose estimation is insufficient since there remains a fundamental ambiguity in determining the global location relative to other objects or people, as shown in Fig. 3
→ 고립된 instance에 대한 reasoning은 object의 intrinsic scale에 대한 ambiguity를 해결할 수 없다.
3.3. Modeling Human-Object Interaction for 3D Spatial Arrangement
Reasoning about the 3D poses of humans and objects independently may produce inconsistent 3D scene arrangements. In particular, objects suffer from a fundamental depth ambiguity: a large object further away can project to the same image coordinates as a small object closer to the camera (see Fig. 3). As such, the absolute 3D depth cannot be estimated.
For instance, knowing that a person is sitting down on the bench can provide a strong prior to determine the 3D orientation of the bench.
Leveraging this requires two important steps:
(1) identifying a human and an object that are interacting
(2) defining an objective function to correctly adjust their spatial arrangements.
Identifying human-object interaction.
We hypothesize that an interacting person and object must be nearby in the world coordinates. In our formulation, we solve for the 6-DoF object pose and the intrinsic scale parameter which places the object into world coordinates and imbues the objects with metric size. We use 3D bounding box overlap between the person and object to determine whether the object is interacting with a person.
- 저자는 world coordinate에서 interacting person과 object가 서로 근처에 있어야한다고 가정한다. Formulation에서 6-DoF object pose와 intrinsic scale parameter를 해결하는데, 이는 object를 world coordinate에 배치하고 object에 metric size를 부여한다.
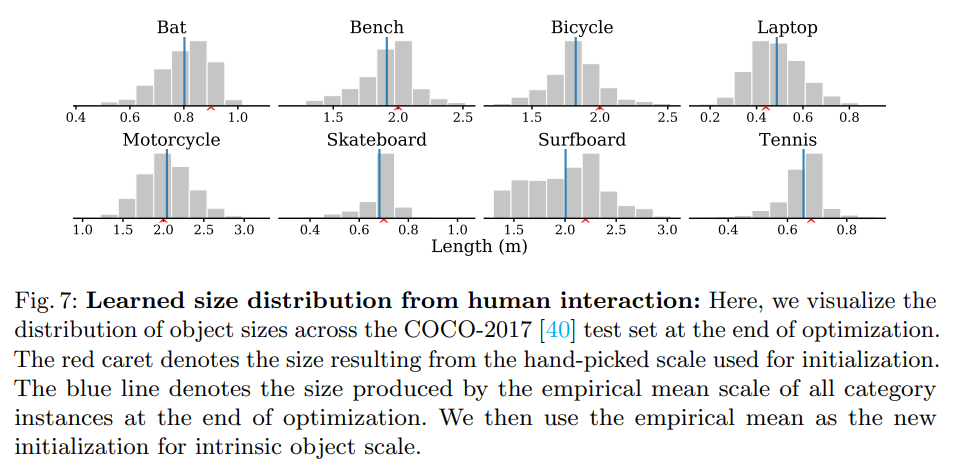
Endowing a reasonable initial scale is important for identifying human-object interaction because if the object is scaled to be too large or too small in size, it will not be nearby the person. We first initialize the scale using common sense reasoning, via an internet search to find the average size of objects (e.g. baseball bats and bicycles are ∼0.9 meters ∼2 meters long respectively). Through our proposed method, the per-instance intrinsic scales change during optimization. From the final distribution of scales obtained over the test set, we compute the empirical mean scale and repeat this process using this as the new initialization (Fig. 7).
- Reasonable한 initial scale을 부여하는 것은 human-object interaction을 식별하는 데 중요하다. object의 크기가 너무 크거나 작게 조정되면 사람 근처에 있지 않기 때문이다. 먼저, object의 평균적인 크기를 찾기 위해 internet search를 통해 상식적인 추론을 사용해서 scale을 초기화한다. (예. 야구 방망이와 자전거는 각각 길이거 ~0.9m, ~2m 이다.) Per-instance intrinsic scale은 optimization 중에 변경된다. Fig.7 에서는 testset에서 얻은 scale의 final distribution에서 empirical mean scale을 계산하고 이를 이용해 새로운 initialization으로 써서 process를 반복하게 된다.
Objective function to optimize 3D spatial arrangements.
Our objective includes multiple terms to provide constraints for interacting humans and objects:
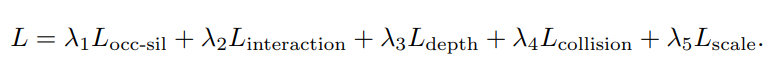
We optimize objective function using a gradient-based optimizer w.r.t. intrinsic scale for the i-th human and intrinsic scale , rotation , and translation for the j-th object instance jointly.
Interaction loss
We first introduce a coarse, instance-level interaction loss to pull the interacting object and person close together:
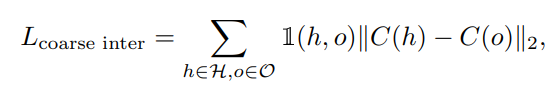
where 1(h, o) identifies whether human h and object o are interacting according to the 3D bounding box overlap criteria described before.
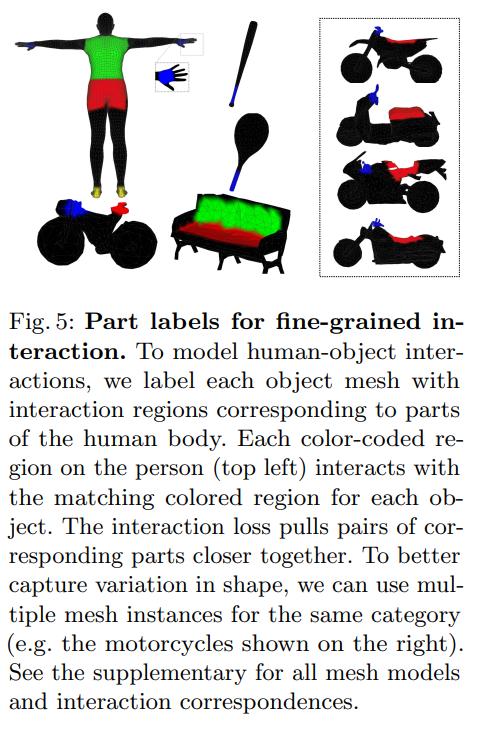
Humans generally interact with objects in specific ways. This can be used as a strong prior for human-object interaction and adjust their spatial arrangement. To do this, we annotate surface regions on the SMPL mesh and on our 3D object meshes where there is likely to be interaction, similar to PROX.
These include the hands, feet, and back of a person or the handlebars and seat of a bicycle, as shown in Fig. 5. To encode spatial priors about human-object interaction (e.g. people grab bicycle handlebars by the hand and sit on the seat), we enumerate pairs of object and human part regions that interact (see supplementary for a full list). We incorporate a fine-grained, parts-level interaction loss by using the part-labels (Fig. 5) to pull the interaction regions closer to achieve better alignment:
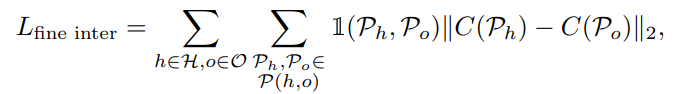
- 사람은 일반적으로 특정한 방식으로 object와 interaction한다. 이것은 human-object interaction에 대한 강력한 prior로 사용될 수 있으며 spatial arrangement를 조정할 수 있다. 이를 위해 PROX와 유사하게 interaction이 있을 가능성이 있는 SMPL mesh 및 3D object mesh의 surface region에 annotation을 한다. 여기에는 Fig. 5와 같이 사람의 손, 발, 등 또는 자전거의 손잡이, 앉는 곳이 포함된다. Human-object interaction (예: 사람들이 자전거 핸들을 손으로 잡고 좌석에 앉음)에 대한 spatial prior를 encoding하기 위해 interaction하는 object 및 human part region의 pair를 나누어놨다. (Supple 참조) 또한 part-label을 사용해서 fine-grained, parts-level interaction loss를 통합해 interaction region을 더 잘 붙이는 역할을 한다.
where and are the interaction regions on the person and object respectively. Note that we define the parts interaction indicator 1(,) using the same criteria as instances, i.e. 3D bounding box overlap. The interactions are recomputed at each iteration.
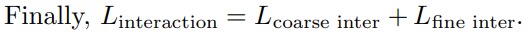
Scale loss
We observe that there is a limit to the variation in size within a category. Thus, we incorporate a Gaussian prior on the intrinsic scales of instances in the same category using a category-specific mean scale:
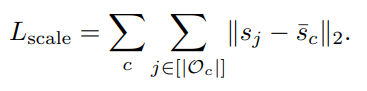
- 저자는 category 내에서 scale의 variation에 한계가 있음을 관찰한다. 따라서, category-specific mean scale을 사용해서 동일한 category에 있는 instance의 intrinsic scale에 Gaussian prior를 통합한다.
We initialize the intrinsic scale of all objects in category c to . The mean object scale is initially set using common sense estimates of object size. In Fig. 7, we visualize the final distribution of object sizes learned for the COCO-2017 [40] test set after optimizing for human interaction. We then repeat the process with the empirical mean as a better initialization for . We also incorporate the scale loss for the human scales with a mean of 1 (original size) and a small variance.
- 먼저 category c에 있는 모든 object의 intrinsic scale을 로 initialize한다. Mean object scale 은 object size에 대한 상식적인 추정치를 사용해서 초기에 설정된다. Fig 7 → human interaction을 optimization한 후 학습한 object size에 final distribution을 visualization한다. 그런 다음 에 대한 더 나은 initialization으로 empirical mean을 사용해서 process를 반복한다. 또한 mean 1 (original size)과 small variance를 사용해서 human scale 에 대한 scale loss를 통합한다.
Ordinal Depth loss
The depth ordering inferred from the 3D placement should match that of the image. While the correct depth ordering of people and objects would also minimize the occlusion-aware silhouette loss, we posit that the ordinal depth loss introduced in Jiang et al [26] can help recover more accurate depth orderings from the modal masks. Using an ordinal depth can give smoother gradients to both the occluder and occluded object. Formally, for each pair of instances, we compare the pixels at the intersections of the silhouettes with the segmentation mask. If at pixel p, instance i is closer than instance j but the segmentation masks at p show j and not i, then we apply a ranking loss on the depths of both instances at pixel p:
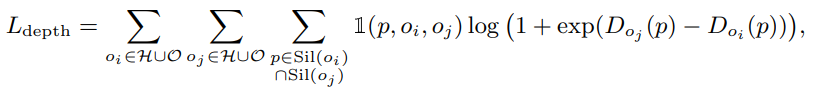
where is the rendered silhouette of instance , is the depth of instance at pixel , and is 1 if the segmentation label at pixel is but .
- 3D placement로 부터 추론된 depth ordering은 image와 match되어야 한다. Human-object의 올바른 depth ordering은 occlusion-aware silhouette loss도 최소화 하지만 [26]에서 도입된 ordinal depth loss가 modal mask에서 더 정확한 depth ordering을 recovery하는 데 도움이 될 수 있다고 가정한다. Ordinal depth를 사용하면 occluded object와 occlude된 사람 모두에 더 smooth한 gradient를 제공할 수 있다. Formulation에서는 각 instance pair에 대해서 silhouette과 segmentation mask 사이의 intersection된 pixel을 비교한다. Pixel p에서 instance i가 instance j보다 가깝지만 segmentation mask가 i가 아닌 j를 표시하는 경우 pixel p에서 두 instance의 depth에 ranking loss를 적용한다.
Collision loss
Promoting proximity between people and objects can exacerbate the problem of instances occupying the same 3D space. To address this, we penalize poses that would human and/or object interpenetration using the collision loss introduced in [6,58].
- Human과 object 사이의 proximity를 촉진하면 instance들이 동일한 3D space를 차지하는 문제가 악화될 수 있다.(Inter-penetration) 이 문제를 해결하기 위해 collision loss를 사용해서 human and/or object interpenetration에 penalty를 부과한다.

Uploaded by N2T