Abstract
Existing methods for MoCap-based action recognition take skeletons as input, which requires an extra manual mapping step and loses body shape information. We propose a novel method that directly models raw mesh sequences which can benefit from the body prior and surface motion. We propose a new hierarchical transformer with intra- and inter-frame attention to learn effective spatial-temporal representations. Moreover, our model defines two self-supervised learning tasks, namely masked vertex modeling and future frame prediction, to further learn the global context for appearance and motion.
- MoCap 기반의 행동 인식을 위한 기존 방법은 input으로 skeleton을 사용하고, 이는 추가적인 manual mapping step을 필요로 하며 body shape 정보를 잃게 된다. 우리는 body prior 정보와 surface motion을 이용할 수 있는 raw mesh sequence를 직접적으로 모델링하는 새로운 방법을 제안한다. 우리는 effective한 spatial-temporal representation을 학습하기 위한 intra- and inter-frame attention을 가진 새로운 hierarchical Transformer를 제안한다. 그리고, 우리 모델은 appearance와 motion의 global context를 더욱 학습하기 위해 masked vertex modeling과 future frame prediction이라는 두 가지 self-supervised learning task를 정의한다.
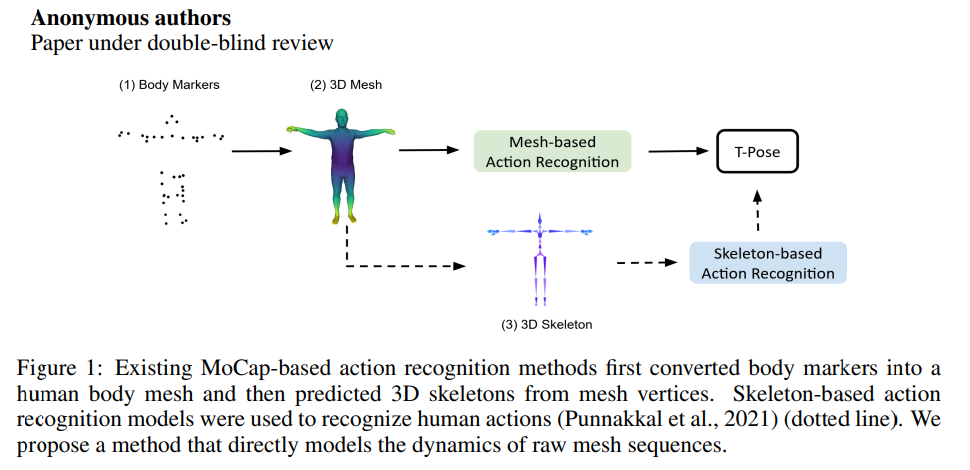
- 기존의 MoCap-based action recognition methods는 body marker를 human body mesh로 변환한다음에 3D skeleton을 예측했다. Skeleton-based action recognition model은 human action을 인식하기 위해 사용되었다. 저자는 raw mesh sequence의 dynamics를 directly하게 modeling하는 method를 제안한다.
1. Introduction
Although those methods achieved advanced performance, they have the following disadvantages: First, they require an extra manual step to map the vertices from mesh to skeleton. Second, skeleton representations lose the information provided by original MoCap data (i.e. surface motion and body shape knowledge). To overcome those disadvantages, we propose a mesh-based action recognition method to directly model dynamic changes in raw mesh sequences, as illustrated in Figure 1.
- 이전 방법들은 높은 성능을 달성했지만, 다음과 같은 단점들이 있다.
- 첫째, mesh에서 skeleton으로 vertex를 mapping하는 추가적인 manual step이 필요하다.
- 둘째, skeleton representation은 원래 MoCap 데이터가 제공하는 정보 (즉, surface motion과 body shape 정보)를 잃어버린다.
- 이러한 단점을 극복하기 위해, 우리는 Figure 1에서 설명된 것처럼 raw mesh sequences의 dynamic changes를 directly modeling하는 mesh-based action recognition 방법을 제안한다.
Though mesh representations provide fine-grained body information, it is challenging to classify temporal mesh sequences for action recognition. First, unlike structured 3D skeletons which have joint correspondence across frames, there is no vertex-level correspondence in meshes (i.e. the vertices are unordered). Therefore, the local connectivity of every single mesh can not be directly aggregated in the temporal dimension. Second, mesh representations encode local connectivity information, while action recognition requires global understanding in the whole spatial-temporal domain.
- Mesh representation은 fine-grained body information을 제공하지만, action recognition을 위한 temporal mesh sequence를 분류하는 것은 어렵다.
- 첫째, frame간에 joint의 대응이 있는 structured 3D skeleton과 달리, mesh에는 vertex-level correspondence가 없다. (즉, vertex가 unordered 이다.) 따라서, 모든 single mesh의 local connectivity를 temporal dimension에서 직접 aggregate 할 수 없다. (vertex간의 correspondence가 없으므로)
- 둘째, mesh representation은 local connectivity information을 encoding하는 반면 action recognition은 전체 spatial-temporal domain에서 global understanding이 필요하다.
To overcome the aforementioned challenges, we propose a novel Spatial-Temporal Mesh Transformer (STMT). We consider the flexibility of a transformer architecture which allows the self-attention mechanism to freely attend to any two vertices, making it possible to learn non-local relationships among vertex patches in the same frame (spatial domains) or across frames (temporal domains). We expect the model to learn spatial-temporal correlation across the entire sequence to alleviate the requirement of explicit vertex correspondence.
- 저자는 위에서 언급한 문제를 극복하기 위해 novel Spatial-Temporal Mesh Transformer (STMT)를 제안한다. 저자는 self-attention mechanism이 임의의 2개의 vertices 사이에 자유롭게 참석할 수 있도록 허용하는 transformer architecture의 flexibility를 고려하여 동일한 frame (spatial domain) 또는 frame 간(temporal domain)에 있는 vertex patch 간의 non-local vertex relationship을 학습할 수 있도록 한다. 저자는 모델이 전체 sequence에 걸쳐 spatial-temporal correlation을 학습하여 explicit vertex correspondence의 requirement를 완화할것으로 기대한다.
Specifically, we first build mesh vertex patches by learning local connectivity information. Then we propose a hierarchical transformer, which performs intra- and inter-frame attention on those patches. We define two self-supervised learning tasks, namely masked vertex modeling and future frame prediction to enable the model to learn from the global context. To reconstruct masked vertices of different body parts, the model needs to learn prior information of human body in spatial dimension. To predict future frames, the model needs to understand meaningful surface movement in the temporal dimension. To this end, our hierarchical transformer pre-trained with those two objectives can further learn spatial-temporal context across entire frames, which improves the downstream action recognition task.
- 구체적으로, 먼저 local connectivity information을 학습하여 mesh vertex patch를 구축한다. 그런 다음 해당 patch에서 intra- & inter-frame attention을 수행하는 hierarchical transformer를 제안한다. 저자는 모델이 global context로 부터 학습할 수 있도록 2가지의 self-supervised learning task를 정의한다. (Masked vertex modeling / future frame prediction) 다른 신체 부위의 masking된 vertex를 reconstruct 하기 위해 모델은 human body에 대한 prior information을 spatial dimension에서 학습해야한다. Future frame을 예측하려면, model은 temporal dimension에서 meaningful surface movement에 대해서 이해해야 한다. 이를 위해 2가지 objective로 pre-train된 hierarchical transformer는 전체 frame에 걸쳐 spatial-temporal context를 추가로 학습할 수 있으므로 downstream action recognition task를 improve한다.
Contribution
We introduce a new hierarchical transformer architecture, which jointly encodes intrinsic and extrinsic representations, along with intra- and inter-frame attention, for spatial-temporal mesh modeling.
- Spatial-Temporal modeling을 위해 intra-, inter-frame attention과 함께 intrinsic, extrinsic representation을 jointly encoding하는 새로운 hierarchical transformer를 소개함.
We design effective and efficient pretext tasks, namely masked vertex modeling and future frame prediction, to enable the model to learn from the spatial-temporal global context.
- 모델이 spatial-temporal global context로 부터 학습할 수 있도록 효과, 효율적인 pretext tasks인 masked vertex modeling과 future frame prediction을 design한다.
Our model achieves superior performance compared to state-of-the-art point-cloud and skeleton models on common MoCap benchmarks.
- SOTA 달성.
3. Method
The input of our model are temporal mesh sequences: where is the frame number, and represents the position of the N vertices of the body mesh in Cartesian coordinates. represents the adjacency matrix of the mesh. Element is one when there is an edge from vertex to vertex , and zero when there is no edge. The mesh representation with vertices and their adjacent matrix is a unified format for various body models such as SMPL, SMPL-H and SMPL-X. In this work, we use SMPL-H body models from AMASS to obtain the mesh sequences, but our method can be easily adopted to other body models.
- 제시한 model의 input은 temporal mesh sequence 이고, 여기서 는 frame number, 는 body mesh의 N개 vertices의 위치를 Cartesian coordinates에서 나타낸다. (그냥 body mesh vertices 들의 좌표값을 말함.) 는 mesh의 adjacency matrix를 뜻하기에, Element 는 vertex가 연결되어있으면 1, 아니면 0을 뜻한다. 이렇게 vertices와 adjacent matrix를 통한 mesh representation은 SMPL, SMPL-H, SMPL-X 와 같은 다양한 body model에서의 unified format이다. 본 논문에서는 AMASS에서의 SMPL-H body model을 사용해 mesh sequence를 얻었지만, 다른 body model에서도 쉽게 적용될 수 있다. (다른 body model을 써도 상관없음.)
Mesh’s local connectivity provides fine-grained information. Previous methods in mesh classification prove that explicitly using surface (e.g., mesh) connectivity can achieve higher accuracy. However, unlike structured 3D skeletons, there is no vertex-level correspondence across frames for mesh sequences, which prevents graph-based models from directly aggregating vertex features in the temporal dimension. Therefore, we propose to first leverage mesh connectivity information to build patches at the frame level, then use a hierarchical transformer which can freely attend to any intra- and inter-frame patches to learn spatial-temporal associations.
- Mesh의 local connectivity는 fine-grained information을 제공함. 이전의 mesh classification methods에서는 explicit하게 surface connectivity를 사용하면 higher accuracy를 얻을 수 있다는 것을 증명했다. 그러나 structured 3D skeleton과 달리, mesh sequence에서는 frame 간의 vertex-level correspondence가 없기 때문에 (mesh에서) graph-based model을 사용하면 temporal dimension에서의 vertex feature를 directly aggregating할 수 없다. 따라서, 저자는 mesh connectivity information을 활용하여 frame-level에서 patch를 구축한 다음에, intra, inter-frame patches에 자유롭게 관여할 수 있는 hierarchical transformer를 사용해 spatial-temporal association을 학습한다.
3가지 구성요소
Surface Field Convolution to form local vertex patches by considering both intrinsic and extrinsic mesh representations.
- intrinsic, extrinsic mesh representation을 고려하여 local vertex patch를 형성하기 위한 Surface Field Convolution
Hierarchical Spatial-Temporal Transformer to learn spatial-temporal correlations of vertex patches.
- vertex patches의 spatial-temporal correlation을 학습하기 위한 Hierarchical Spatial-Temporal Transformer
Self-Supervised Pre-Training to learn the global context in terms of appearance and motion.
- appearance와 motion의 global context를 학습하기 위한 Self-Supervised Pre-Training
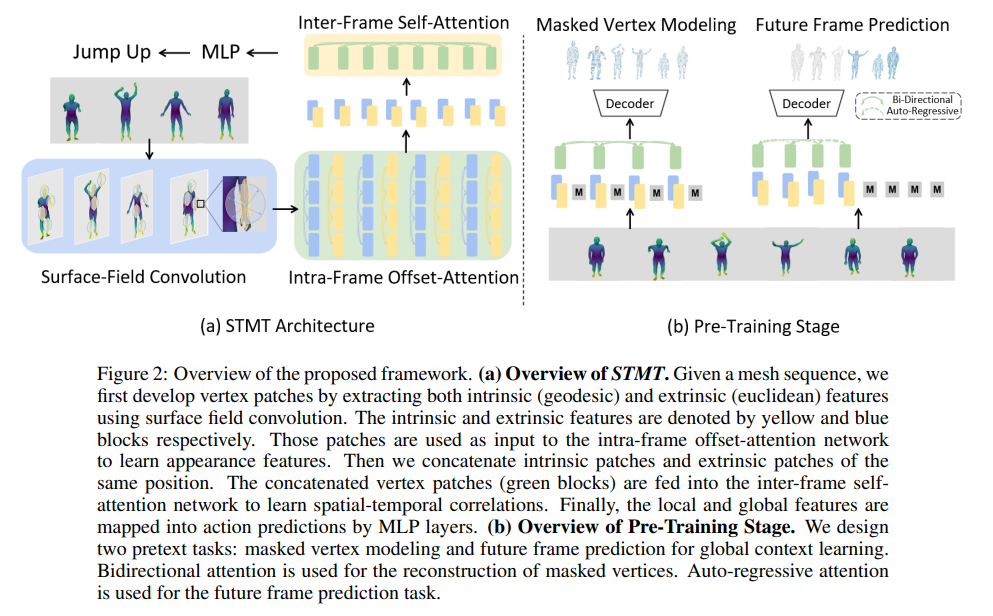
- 전체 Framework Overview.
- (a)는 STMT의 overview. mesh sequence가 주어지면, surface field convolution을 사용해서 intrinsic (geodesic), extrinsic (euclidean) feature를 뽑고 이를 통해 vertex patch를 develop한다. Intrinsic, extrinsic feature는 그림에서 노란색, 파란색임. 이 patch들은 intra-frame offset-attention network의 input으로 사용되어서 appearance feature를 학습한다. (1개로 줄어든 것인 듯 하다.) 그리고 나서 동일한 위치의 intrinsic patch와 extrinsic patch를 concatenate한다. concatenate된 vertex patch (초록색 block)은 inter-frame self-attention network에 통과되어 spatial-temporal correlation을 학습한다. 최종적으로 local, global feature는 MLP layer를 통해 action prediction에 mapping 된다.
- (b)는 Pre-Training Stage의 overview. 2가지의 pretext tasks : global context learning을 위한 masked vertex modeling, future frame prediction. Bidirectional attention은 masked vertices를 reconstruction 하기 위해 사용되었음. Auto-regressive attention은 future frame prediction task를 위해 사용됨.
3.2. Surface Field Convolution
Because displacements in grid data are regular, traditional convolutions can directly learn a kernel for elements within a region. However, mesh vertices are unordered and irregular. Considering the special mesh representations, we represent each vertex by encoding features from its neighbor vertices inspired by (Qi et al., 2016; 2017).
- Grid data에서 displacements는 규칙적이고, traditional convolution은 region 내의 element에 대한 kernel을 direct하게 학습할 수 있다. 그러나, mesh vertices는 unordered하고 irregular 하다. special mesh representation을 고려해서 neighbor vertices로 부터의 feature를 encoding해서 각 vertex를 representation 한다. (Neighbor vertices의 feature로 각 vertex를 표현하겠다.)
To fully utilize meshes’ local connectivity information, we consider the mesh properties of extrinsic curvature of sub-manifolds and intrinsic curvature of the manifold itself. Extrinsic curvature between two vertices is approximated using Euclidean distance. Intrinsic curvature is approximated using Geodesic distance, which is defined as the shortest path between two vertices. We propose a light-weighted surface field convolution to build local patches, which can be denoted as:
- Mesh의 local connectivity information을 fully utilize 하기 위해, 저자는 sub-manifolds의 extrinsic curvature, manifold 그 자체의 intrinsic curvature라는 mesh properties를 고려한다.
- 두 vertices 사이의 Extrinsic curvature는 Euclidean distance를 사용해 근사한다.
- Intrinsic curvature는 두 vertex 사이의 가장 짧은 path로 정의된 geodesic distance를 사용해서 근사한다
- 저자는 local patch를 build하기 위한 light-weighted surface convolution를 제안한다.
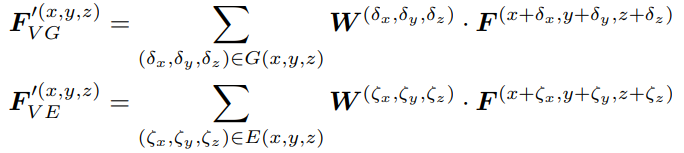
는 vertex (x, y, z) 주변의 local region 이다. 여기서, k-nearest-neighbor를 사용해서 local vertices를 sampling 한다. 와 는 geodesic, euclidean space에서의 spatial displacement이다. 는 (x, y, z)의 좌표를 가진 vertex의 feature 이다.
⇒ W는 무엇? 아마 weight인듯.
- 따라서, 특정 (x, y, z) 좌표의 point feature인데 각각 geodesic space인지, euclidean space인지에 따라서 nearest neighbor들이 다르게 정의되기 때문에 이런식으로 나누어서 표현한 듯 하다.
3.3 Hierarchical Spatial-Temporal Transformer
We propose a hierarchical transformer which consists of intra-frame and inter-frame attention. The basic idea behind our transformer is three-fold:
(1) Intra-frame attention can encode connectivity information from the adjacency matrix, while such information can not be directly aggregated in the temporal domain because vertices are unordered.
(2) Frame-level offset-attention can be used to mimic Laplacian operator to learn effective spatial representations.
(3) Inter-frame self-attention can learn feature correlations in the spatial-temporal domain.
- 저자는 intra-frame, inter-frame attention으로 구성된 hierarchical transformer를 제시했고, 이는 3가지 아이디어를 갖고 있다.
(1) Intra-frame attention은 adjacency matrix에서 connectivity information을 encoding할 수 있지만, vertices가 unordered 하기 때문에 temporal domain에서 해당 정보를 직접 aggregate 할 수 없다.
(2) Frame-level offset-attention은 효과적인 spatial representation을 학습하기 위해 Laplacian operator를 모방하는 데 사용될 수 있다.
(3) Inter-frame self-attention은 spatial-temporal domain에서 feature correlation을 학습할 수 있다.
3.3.1 Intra-Frame Offset-Attention
Graph convolution networks (Bruna et al., 2014) show the benefits of using a Laplacian matrix to replace the adjacency matrix , where is the diagonal degree matrix. Inspired by this, offset-attention has been proposed and achieved superior performance in point-cloud classification and segmentation tasks (Guo et al., 2021). We adapt offset-attention to attend to vertex patches. Specifically, the offset-attention layer calculates the offset (difference) between the self-attention (SA) features and the input features by element-wise subtraction. Offset-attention is denoted as:
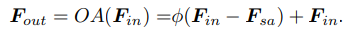
- GCN은 Laplacian Matrix 을 adjacency matrix 대신 사용하는 것에 대한 이점을 보여준다. 여기서, 는 diagonal degree matrix이다. 여기서 부터 영감을 받아 offset-attention은 다른 task에서 superior performance를 보임. 저자는 offset-attention을 vertex patch에 집중하도록 적용한다. 구체적으로, offset-attention layer는 element-wise subtraction(뺄셈)에 의해 self-attention (SA) feature와 input feature 간의 offset(차이)를 계산함. offset-attention은 위의 식과 같이 표시된다.
where denotes a non-linear operator. is proved to be analogous to discrete Laplacian operator, i.e. ≈ . As Laplacian operators in geodesic and euclidean space are expected to be different, we propose to use separate transformers to model intrinsic patches and extrinsic patches. Specifically, the aggregated feature for vertex V is denoted as:
- 여기서 는 non-linear operator이다. 는 discrete Laplacian operator와 유사하다는 것이 입증되었다고 한다. ( ≈ ) Geodesic, euclidean space에서의 Laplacian operator가 서로 다르기 때문에 intrinsic patch와 extrinsic patch를 modeling 하기 위한 별도의 transformer를 사용하는 것을 제안한다. 구체적으로, vertex V에 대한 aggregated feature는 다음과 같이 표시된다.
- 이것이 아까 appearance feature라고 하는 것 같음. 각 intra-frame offset attention을 통해서 각 vertex patch에서의 feature를 구하고, 이를 weight에 통과시켜서 1개로 만듬. 그리고 geodesic, euclidean space에서의 feature를 concat하여 inter-frame self-attention에 넘겨주는 것.
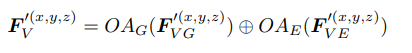
Here and are local patches learned using Equ. 1 and Equ. 2. denotes the local patch for position , where . The weights of and are not shared.
- 여기서 와 는 Equ1 과 2를 통해 학습되는 local patch이다. 는 (x, y, z) position의 local patch를 말하고 이다. weight 와 는 공유되지 않는다.
3.3.2 Inter-Frame Self-Attention
Given which encodes local connectivity information, we use self-attention (SA) (Vaswani et al., 2017) to learn semantic affinities between different vertex patches across frames. Specifically, let be the query, key and value, which are generated by applying linear transformations to the input features as follows:
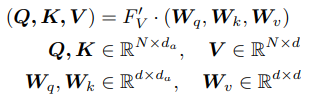
- Local Connectivity information을 encoding 하는 가 주어지면, self-attention을 사용해서 다른 frame의 다른 vertex patch 사이의 의미론적 유사성를 학습한다. 구체적으로, (query, key, value)는 input feature 에 linear transformation을 적용해서 생성한다.
where , and are the shared learnable linear transformation, and is the dimension of the query and key vectors. Then we can use the query and key matrices to calculate the attention weights via the matrix dot-product:
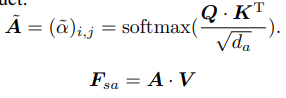
- , , 는 shared learnable linear transformation 이고 는 query, key vector의 dimension 이다. 그리고 나서 query, key matrix를 사용해서 attention weight를 계산한다. (matrix dot-product)
The self-attention output features are the weighted sums of the value vector using the corresponding attention weights. Specifically, for a vertex patch in position , its aggregated feature after inter-frame self-attention can be computed as: , where belongs to the Cartesian coordinates of .
- self-attention output feature 는 해당 attention weight를 사용한 value vector의 weighted sum이다. 구체적으로, (x, y, z) position의 vertex patch에 대해, inter-frame self-attention 후의 aggregated feature는 다음과 같이 계산된다. 여기서 는 의 Cartesian coordinate에 속한다.
3.4 Self-Supervised Pre-Training.
Self-supervised learning for temporal 3D sequences (i.e. point cloud, 3D skeleton) remains to be challenging and has not been fully explored. There are two possible reasons: (1) self-supervised learning methods rely on large-scale datasets to learn meaningful patterns (Cole et al., 2022). However, existing MoCap benchmarks are relatively small compared to 2D datasets like ImageNet (Deng et al., 2009). (2) Self-supervised learning for 3D data sequences is computationally expensive in terms of both memory and speed. In this work, we first propose a simple and effective method to augment existing MoCap sequences, and then define two effective and efficient self-supervised learning tasks, namely masked vertex modeling and future frame prediction, which enable the model to learn global context.
- Self-supervised learning은 temporal 3D sequences (point cloud, 3D skeleton) 에서는 여전히 challenging 한데, 이는 2가지의 이유가 있어서임. (1) self-supervised learning method는 large-scale dataset에 의존하는데, 기존 MoCap benchmark는 너무 작음. (2) 3D data sequence에 대한 self-supervised learning은 memory와 speed 측면에서 cost가 큼. 본 논문에서는 기존의 MoCap sequence를 augmentation하기 위한 간단하고 효과적인 방법을 먼저 제안하고, 이후 모델이 global context를 학습할 수 있도록 하는 두 가지 효과적이고 효율적인 self-supervised learning task인 mask vertex modeling과 future frame prediction을 정의함.
3.4.1 Data Augmentation Through Joint Shuffle
We propose a simple yet effective approach to augment SMPL-H sequences by shuffling body pose parameters. Specifically, we split SMPL-H pose parameters into five body parts: bone, left/right arm, and left/right leg. We use to denote the SMPL-H pose indexes of the five body parts. Then we synthesize new sequences by randomly selecting body-parts from five different sequences.
- 저자는 body pose parameter를 shuffling함으로써 SMPL-H sequence를 augment 하기 위한 simple하고 effective한 방식을 소개한다. 구체적으로, SMPL-H pose parameter를 5개의 body parts로 나눈다. (bone, left/right arm, left/right leg) Index는 로 표시. 그 다음, 5가지 다른 sequence에서 body parts를 임의로 선택해서 새로운 sequence를 합성한다.
We keep the temporal order for each part such that the merged action sequences have meaningful motion trajectories. The input to Joint Shuffle are SMPL-H pose parameters , where b is the sequence number, t is the frame number, and is the joint number. We randomly select the shape and dynamic parameters from one of the five SMPL-H sequences to compose a new SMPL-H body model. Given SMPL-H sequences, we can synthesize number of new sequences.
- 각 part에 대해 temporal order를 유지하여 병합된 action sequence가 의미 있는 motion trajectory를 갖게 한다. Joint Shuffle의 input은 SMPL-H pose parameter 이고, 여기서 b는 sequence number, t는 frame number, n은 joint number이다. 저자는 새로운 SMPL-H body model을 구성하기 위해 5개 중 1개의 SMPL-H sequence에서 random하게 shape, dynamic parameter를 선택한다. b개의 SMPL-H seqeucne가 주어지면, 개수 만큼의 새로운 sequence를 synthesize할 수 있다.

3.4.2 Masked Vertex Modeling with Bi-directional Attention
To fully activate the inter-frame bi-directional attention in the transformer, we design a self-supervised pretext task named Masked Vertex Modeling (MVM). The model can learn human prior information in the spatial dimension by reconstructing masked vertices of different body parts. We randomly mask percentages of the input vertex patches, and force the model to reconstruct the full sequences.
- Transformer에서 inter-frame bi-directional attention을 fully activate 하기 위해, 저자는 self-supervised pretext task인 Masked Vertex Modeling (MVM)를 제안한다. Model은 서로 다른 body part의 masked vertex를 복원함으로써 spatial dimension에서의 human prior를 학습할 수 있다. 저자는 퍼센트 만큼의 input vertex patch를 randomly masking 하고, model이 full sequence를 복원하도록 한다.
Moreover, we use bi-directional attention to learn correlations among all remaining local patches. Each patch will attend to all patches in the entire sequence. It models the joint distribution of vertex patches over the whole temporal sequences as the following product of conditional distributions, where is a single vertex patch:
게다가, bi-directional attention을 사용하여 모든 나머지 local patch 사이의 correlation을 학습한다. 각 patch는 모든 patch에대해 attention을 계산한다. 이는 전체 temporal sequence 에 걸쳐 vertex patch의 joint distribution을 다음과 같은 conditional distribution의 곱으로 modeling 한다. 여기서 는 single vertex patch 이다. ⇒ 아래의 식과 같은 conditional distribution은 왜 표기한 건지 모르겠음. 아마 각 joint patch들이 서로에 대해 연산하고있기 때문이라고 생각은 되는데 오히려 혼란을 일으키는 것 같음.
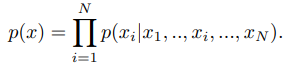
Where is the number of patches in the entire sequence after masking. Every patch will attend to all patches in the entire sequence. In this way, bi-directional attention is fully-activated to learn spatial-temporal features that can accurately reconstruct completed mesh sequences.
N은 masking 후 전체 sequence 에서의 patch 수이다. 모든 patch는 전체 sequence의 모든 patch에 attention을 계산한다. 이렇게 함으로써 bi-directional attention이 fully-activate되어 completed mesh sequence를 정확하게 reconstruct할 수 있는 spatial-temporal feature를 학습한다.
3.4.3 Future Frame Prediction with Auto-Regressive Attention
As action recognition requires the model to understand the global context, we propose the future frame prediction (FFP) task. Specifically, we mask out all the future frames and force the transformer to predict the masked frames. We propose to reconstruct all future frames in a single forward pass. For auto-regressive attention, we model the joint distribution of vertex patches over a mesh sequence as the following product of conditional distributions, where is a single patch at frame :
- Action recognition은 global context를 이해해야 하므로 future frame prediction (FFP) task를 제안한다. 구체적으로, 모든 future frame을 masking하고 transformer가 masking된 frame을 예측하도록한다. 저자는 single forward pass에서 모든 future frame을 reconstruction할 것을 제안한다. Auto-regressive attention을 위해 mesh sequence 에 대한 vertex patch의 joint distribution을 conditional distribution의 곱으로 modeling한다. 여기서 는 frame 에서의 single patch이다.
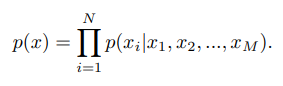
Where is the number of patches in the entire sequence after masking. , where is the number of patches in a single frame. Each vertex patch depends on all patches that are temporally before it. The unidirectional attention helps the model to understand movement patterns and trajectories, which is beneficial for the downstream action recognition task.
- 여기서 은 masking 후에 전체 sequence 에서의 patch 수이다. , 여기서 n은 단일 frame의 patch 수이다. 각 vertex patch는 temporal하게 그 앞에 있는 모든 patch에 따라 달라진다. unidirectional attention은 model이 movement pattern과 trajectory를 이해하는 데 도움이 되며, 이는 downstream action recognition task에 유용하다.
⇒ MVM과 FFP는 각각 bi-directional, uni-directional 하게 transformer를 pre-train 시킴으로써 contextual한 정보를 모델이 미리 들고있게 만드는 것이 목표임. Transformer는 intra & inter frame attention transformer 구조를 모두 사용하는 것.
3.5. Training
In the pre-training stage, we use PCN (Yuan et al., 2018) as the decoder to reconstruct masked vertices and predict future frames. The decoder is shared for the two pre-text tasks.
Since mesh vertices are unordered, the reconstruction loss and future prediction loss should be permutation invariant. Therefore, we use Chamfer Distance (CD) as the loss function to measure the difference between the model predictions and ground truth mesh sequences.
- Pre-trainig stage에서는 PCN이라는 것을 decoder로 사용해서 masked vertex recon과 future frame prediction을 진행함.
- Mesh vertices는 unordered하기 때문에 reconstruction loss와 future prediction loss는 permutation invariant 해야해서 Chamfer Distance (CD) loss function을 사용하였음.
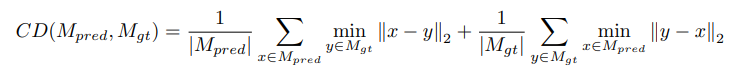
CD (10) calculates the average closest euclidean distance between the predicted mesh sequences and the ground truth sequences . The overall loss is a weighted sum of masked vertex reconstruction loss and future frame prediction loss:
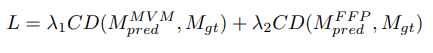
In the fine-tuning stage, we replace the PCN decoder with an MLP head. Cross-entropy loss is used for model training.
4. Experiment
KIT → 56 class, 6570 sequence 포함
BABEL → 346 subject를 43시간동안 찍음. 60 class, 21653 sequence
train / test / valid ratio 70, 15, 15
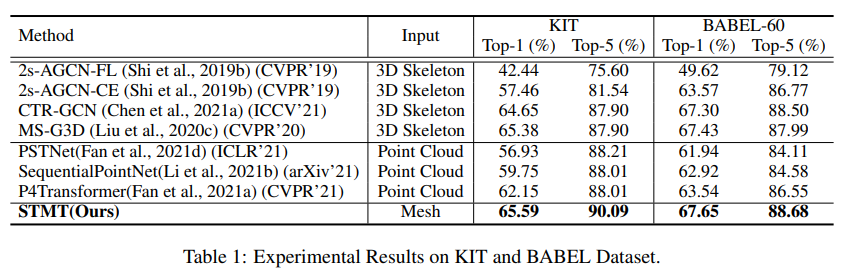
Skeleton based action recognition model은 SMPL-H에서 25개의 joint 뽑아서 사용했고, point cloud는 mesh vertex 그대로 다 사용.
4.5. Ablation Study
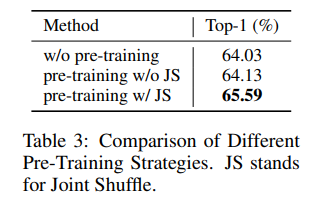
Note that Joint Shuffle is used in all of the self-supervised learning experiments (last three rows). Comparing the last three rows with the second row, we observe that there is a consistent improvement using self-supervised pre-training.
- Joint Shuffle은 아래 3개의 self-supervised learning experiments에서 사용되었음. 제시한 방법들이 전부 성능이 오름.
Moreover, the downstream task can achieve better performance with MVM compared to FFP. One probable reason is that the single task for future frame prediction is more challenging than masked vertex modeling, as the model can only attend to frames in the past and no movement information is available from nearby frames.
- MVM이 FFP보다 상승폭이 큰데 1가지 그럴듯한 이유는 future frame prediction model이 과거 프레임 정보만 사용할 수있고 주변 frame의 movement information은 사용할 수 없어서 masked vertex modeling 보다 challenging한 task여서 그런것 같다고 함.

4.6. Analysis
Joint Shuffle에 대한 실험.
Masking Ratios에 대한 실험.
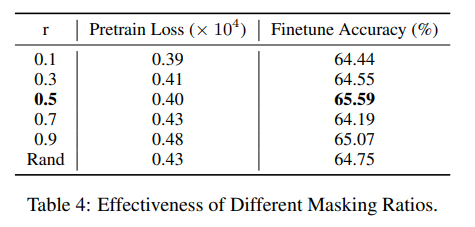
- Pre-training에서 vertex masking 후 recon 하는데 이에 대해서 비율을 얼마나 주었을 때 가장 성능이 좋았는지 확인.
Pre-Training에서 Mesh Sequence의 개수에 따른 실험.

- Joint Shuffle이 추가 비용 없이 dataset 크기를 확대할 수 있으므로 모델 성능을 더욱 향상시킬 수 있었음.
5. Conclusion
In this work, we propose a novel approach for mocap-based action recognition. Unlike existing methods that rely on skeleton representation, our proposed STMT directly models the raw mesh sequences. Our method encodes both intrinsic and extrinsic features in vertex patches, and uses a hierarchical transformer to freely attend to any two vertex patches in the spatial and temporal domain. Moreover, two self-supervised learning tasks, namely Masked Vertex Modeling and Future Frame Prediction are proposed to enforce the model to learn global context.
- MoCap-based action recognition이라는 novel approach 제시. Skeleton representation에 의존하는 기존 방법과 달리, 제안된 STMT는 raw mesh sequence를 direct하게 modeling 한다. 본 논문의 방법은 vertex patch의 extrinsic, intrinsic feature를 모두 encoding하고 hierarchical transformer를 사용해서 spatial temporal domain에 있는 어떤 두 vertex 사이에도 자유롭게 연산하게 되는 것이다. 또한 model이 global context를 학습하도록 하기 위해 Masked Vertex Modeling 및 Future Frame Prediction이라는 두 가지 self-supervised learning task가 제안된다.
Uploaded by N2T