Abstract
Capturing realistic human scene interactions, while dealing with occlusions and partial views, is challenging. We address this problem by proposing LEMO: LEarning human MOtion priors for 4D human body capture. By leveraging the large scale motion capture dataset AMASS [38], we introduce a novel motion smoothness prior, which strongly reduces the jitters exhibited by poses recovered over a sequence. Furthermore, to handle contacts and occlusions occurring frequently in body-scene interactions, we design a contact friction term and a contact-aware motion infiller obtained via per-instance self-supervised training.
- Occlusion과 partial view를 다루면서 realistic human scene interaction을 capture하는 것은 어려운 일이다. 저자는 LEMO : LEarning human MOtion priors for 4D human body capture를 제안해서 이 문제를 해결한다. 논문에서는 large scale motion capture dataset AMASS를 활용해서 novel motion smoothness prior를 제시하였는데 이는 sequence에 걸쳐 복구된 포즈에 의해 나타나는 jittering을 강하게 줄인다. 또한 body-scene interaction에서 자주 발생하는 contact과 occlusion을 처리하기 위해 per-instance self-supervised training을 통해 얻은 contact friction term과 contact-aware motion infiller를 디자인한다.
1. Introduction
Contributions
1) a novel marker-based motion smoothness prior that encodes the “whole-body” motion in a learned latent space, which can be easily plugged into an optimization pipeline;
- Optimization pipeline에 쉽게 연결할 수 있는 학습된 latent space에서의 “whole-body” motion을 encoding하는 새로운 marker-based motion smootheness prior
2) a novel contact-aware motion infiller that can be adapted to per-test-instance via self-supervised learning;
- self-supervised learning을 통해 test-instance별로 조정할 수 있는 novel contact-aware motion infiller
3) a new optimization pipeline that explores both learned motion priors and the physics-inspired contact friction term for scene-aware human motion capture.
- Scene-aware human motion capture를 위해 학습된 motion prior와 physics-inspired contact friction term을 모두 탐색하는 새로운 optimization pipeline
3. Method
Notation은 PROX-D 논문과 동일
3.2. Per-frame Fitting (Stage 1)
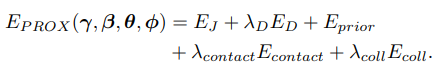
PROX는 per-frame fitting을 통해서 SMPL-X parameter를 찾아낸다. 각 term들에 대해서는
는 Openpose를 통해 예측된 2D joint와 projection된 SMPL-X joints와의 loss
는 depth frame으로 부터 얻은 human point cloud와 camera에서 보이는 SMPL-X surface point 사이의 3D distance
는 body pose, shape, facial expression의 regularization
는 scene vertex와 body에서 pre-defined된 contact vertex set과의 contact을 encourage함.
는 scene-body inter-penetration을 penalize하는 term
3.3. Temporally Smooth Motion
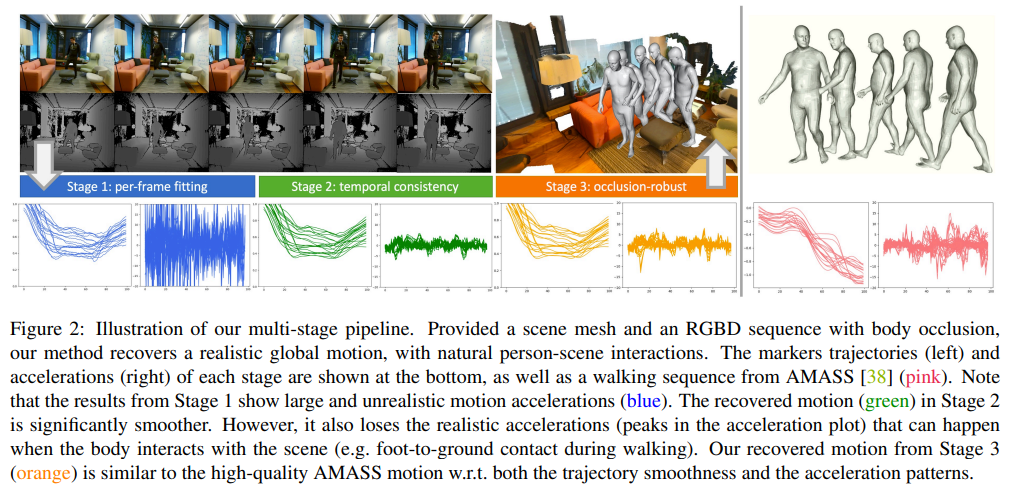
In Stage 2, we process the output of Stage 1. In order to obtain smooth and realistic motion, we design a motion smoothness prior and a physics-inspired friction term, which are then used in an optimization algorithm.
- Stage 2에서는 Stage 1에서의 output을 처리한다. smooth, realistic motion을 얻기위해 motion smoothness prior와 physics-inspired friction term을 추가해서 optimization algorithm에 사용한다.
Motion smoothness prior.
Instead of enforcing smoothness explicitly on body joints, we propose to learn a latent space of smooth motion. To this end, we train an autoencoder with high-quality data from AMASS. The input to our network is a sparse set of body surface markers. (81 markers)
- Body joint에 explicit smoothness를 적용하는 대신 smooth motion에 대한 latent space를 학습하는 것을 제안함. 이를 위해 AMASS의 high-quality data를 가지고 auto-encoder를 학습함. Network의 input은 body surface marker set임. (marker는 81개.)
Given a sequence of T frames, at each time t we compute the time difference of marker locations and concatenate them to a vector of length S. Then the entire sequence is represented by a 2D feature map . The network encoder converts to its latent representation Z. We regard the time series as an image and perform 2D convolutions. We do not downsample the input, so and Z have identical temporal resolution. Therefore, the network captures spatio-temporal correlations with a large receptive field in the latent space, which can represent motion of overlapped body parts. The decoder has a symmetric architecture with deconvolution layers.
- T-frame sequence가 주어지면 각 시간 t에서 marker location의 차이를 계산하고 이를 길이 S의 vector에 연결한다. 그 다음 전체 sequence는 2D feature map()으로 표시된다. Network encoder 는 를 latent representation Z로 변환한다. 논문에서는 time series 를 image로 간주하고 2D convolution을 적용한다. 저자는 input을 downsample하지 않기 때문에 와 Z는 동일한 temporal resolution을 가진다. 따라서, network는 overlap된 body part의 motion을 나타낼 수 있는 latent space의 large receptive field와 spatio-temporal correlation을 캡처한다. Decoder는 deconvolution layer가 있는 symmetric architecture를 가지고 있다.
We train our autoencoder on the AMASS dataset with the following loss:
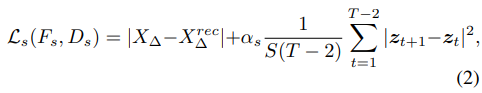
- Autoencoder를 학습하기 위한 loss는 다음과 같다.
where the first term is the reconstruction loss minimizing discrepancy between and , and the second term minimizes the 1st order derivative of the latent sequence . weights the contribution of the second term.
- 1번째 term은 와 recon된 사이의 discrepancy를 minimizing 하는 loss. 2번째 term은 latent sequence 사이의 1st order derivative를 minimize시키는 term. (Smoothness를 위해서 하는 작업인 것 같음.)
With a pretrained autoencoder, we design a smoothness loss to regularize motions over time. Specifically, we take the per-frame bodies obtained from Stage 1, and concatenate their markers into a velocity map . We feed this map into , encoding it into . The smoothness loss is given by
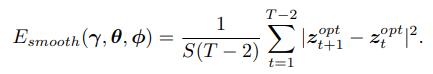
- 저자는 시간이 지남에 따른 motion을 regularize하기 위해 smoothness loss를 디자인했다. 구체적으로 1단계에서 얻은 per-frame body를 가져와서 marker와 velocity map에 연결한다. 그리고 이 map을 encoding시켜서 얻은 z값을 가지고 smoothness하게 loss를 정의한다.
AMASS를 사용해서 적절한 latent space를 얻도록 autoencoder를 학습시킴. 그리고나서 PROX dataset에서는 pre-defined encoder를 사용해서 찾은 latent space 값들 사이의 smoothness loss를 줌으로써 long-range correlation을 더 잘 capturing할 수 있음.
Contact friction modelling
The contact term used in Eq. 1 only considers body-scene proximity, and hence cannot prevent skating artifacts (e.g. a person slides when sitting on a chair). To overcome this issue, we design a contact term that incorporates stationary frictions. Compared to methods which work with foot joints, our contact friction term is based on the body and scene mesh, with a more generic human-scene interaction setting, and considers also other body parts such as gluteus.
- 이전 contact term은 body-scene 사이의 근접성만을 고려하므로 skating artifacts(의자에 앉을 때 미끄러짐)을 고려할 수 없다. 이 문제를 극복하기 위해 고정 마찰을 포함하는 contact term을 디자인한다. 본 논문에서 제시한 term은 foot joint를 고려하는 방법보다 일반적인 human-scene interaction setting을 사용하여 body, scene mesh를 기반으로하며 gluteus와 같은 다른 신체 부위도 고려한다.
Specifically, we pre-define a set of “contact friction” vertices , corresponding to 194 foot and 113 gluteus vertices. When contact occurs (i.e. the distance between a body vertex to the scene mesh is smaller than 0.01m), the velocity of the contacted vertex in is regularized: the component along the scene normal n should be non-negative to prevent interpenetration, and the component tangential to the scene, , should be small to prevent sliding. Formally, this gives us:
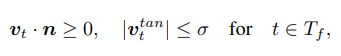
- 구체적으로는 194개의 발과 113개의 gluteus에 해당하는 contact friction vertex set을 미리 정의한다. Contact이 발생하면(즉, body vertex와 scene mesh 사이의 거리가 0.01m 미만인 경우) 에서 접촉된 vertex에 대한 속도 가 정규화된다. Component 는 scene normal에 따라서 interpenetration을 방지하기 위해 negative가 아니어야 하며 scene에 접하는 component 는 sliding을 방지하기 위해 작아야한다.
where is the set of frames in which vertex and scene are in contact, and is a small number as a threshold. Based on this, we formulate our contact friction term as:
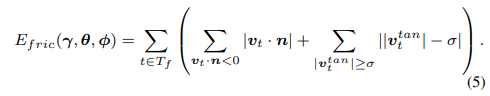
- 는 scene과 vertex가 contact한 frame set이고 는 threshold. 이를 기반으로 loss가 작성됨
1st term은
2nd term은
Stage 2 fitting.
PROX term에 위에 term을 합쳐서 fitting 시킴.

3.4. Recovering Motion under Occlusion
Motion infilling network.
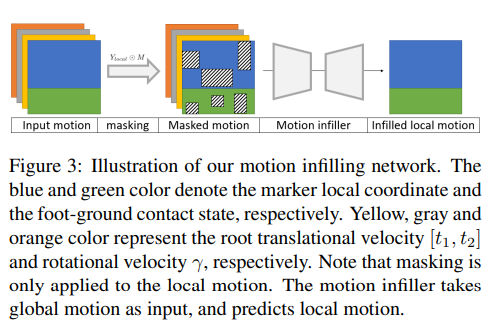
Our infiller takes body surface markers as input, and infers motions and contact states jointly. Here we represent markers in a local coordinate system as in [21, 28]: for each frame t, marker locations are relative to the position of the body root, which is the pelvis projected to the ground. In addition, the body global configuration is represented by the root’s translational velocity and rotational velocity around the upaxis. Moreover, we select two markers per foot and check whether they contact with the ground at each frame. The marker is deemed in contact with the ground if its velocity is smaller than 20cm/s and its height above the ground is lower than 10cm. Finally, we arrange the motion sequence into a 3D tensor with 4 channels. In the first channel , each column denotes a vector concatenating local body marker positions and contact labels of this frame, and P is the vector dimension. The last three channels consist of the repeated entries of global trajectory velocities , and respectively, which allows us to couple global and local motion more closely than [21, 28].
- 논문에서 제시하는 infiller는 body surface marker를 input으로 사용하고 motion과 contact state를 동시에 inferring한다. 여기서 저자는 이전 논문들과 같이 local coordinate system에서 marker를 나타낸다. 각 frame t에 대해서 marker location은 ground에 projection된 pelvis에 relative한 position에 해당한다. 게다가, body global configuration은 root의 translational velocity와 rotational velocity로 표시된다. 또한 발마다 2개의 marker를 선택해서 매 프레임마다 지면에 닿는지 확인한다. Velocity가 20cm/s 미만이고 높이가 ground로 부터 10cm 미만이면 marker가 지면에 contact된 것으로 간주된다. 마지막으로, motion sequence를 4-channel의 3D tensor로 arrange한다. 첫 번째 channel 에서 각 column은 이 frame에서 local body marker location과 contact label을 연결하는 vector를 나타내며 P는 vector dimension이다. 마지막 3개 channel 는 반복되는 entry (global trajectory velocity , and ) 로 이루어져있고, 이는 global과 local motion을 결합할 수 있다.
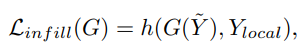
where h(·) is the L1 loss for local marker coordinates, and the binary cross entropy (BCE) loss for the contact labels.
(element-wise matrix multiplication)
masked motion
Y는 P x T (marker 개수 X Temporal axis)
여기서 1채널은 contact label + 3개는 transitional, rotational velocity
Local coordinate 사용. (Translation이랑 rotation으로 좌표계를 설명하는 것 같음.)
1st channel의 Column은 root relative coordinate를 flatten해서 이어붙인것이 위쪽, 그리고 발에 대한 contact label이 아래쪽.
그렇게 하면 가장 앞채널이 motion에 대한 내용이 될 것이고 (각 joint에 대한 relative coordinate들이 pixel에 차있으므로), 이를 가리면 masked motion.
Uploaded by N2T