1. Introduction
To understand the scene of multiple persons, the model needs to not only describe the individual action of each actor in the context, but also infer their collective activity.
However, modeling the relation between actors is challenging, as we only have access to individual action labels and collective activity labels, without knowledge of the underlying interaction information.
It is expected to infer relation between actors from other aspects such as appearance similarity and relative location.
In this work, we address the problem of capturing appearance and position relation between actors for group activity recognition. Our basic aim is to model actor relation in a more flexible and efficient way, where the graphical connection between actors could be automatically learned from video data, and inference for group activity recognition could be efficiently performed.
Specifically, we propose to model the actor-actor relation by building a Actor Relation Graph (ARG), illustrated in Figure 1, where the node in the graph denotes the actor’s features, and the edge represents the relation between two actors.
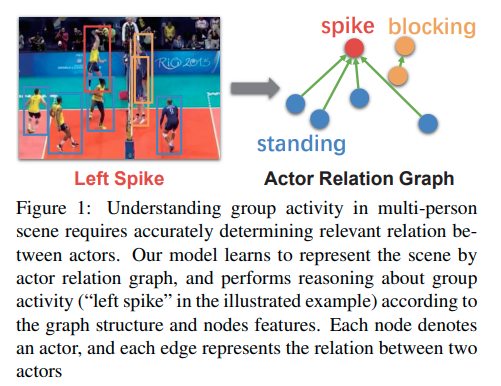
Thanks to the operation of graph convolution [29], the connections in ARG can be automatically optimized in an end-to-end manner. Thus, our model can discover and learn the potential relations among actors in a more flexible way. Once trained, our network can not only recognize individual actions and collective activity of a multi-person scene, but also on-the-fly generate the video-specific actor relation graph, facilitating further insights for group activity understanding.
To further improve the efficiency of ARG for long-range temporal modeling in videos, we come up with two techniques to sparsify the connections in ARG. Specifically, in spatial domain, we design a localized ARG by forcing the connection between actors to be only in a local neighborhood.
video 캡쳐는 매우 조밀하게 되지만 의미는 천천히 변한다. Instead of connecting any pair frame, we propose a randomized ARG by randomly dropping several frames and only keeping a few. This random dropping operation is able to not only greatly improve the modeling efficiency but also largely increase the diversity of training samples, reducing the overfitting risk of ARG.
We report performance on two group activity recognition benchmarks: the Volleyball dataset [25] and the Collective Activity dataset [7].
The major contribution of this paper is summarized as follows:
- We construct flexible and efficient actor relation graphs to simultaneously capture the appearance and position relation between actors for group activity recognition. It provides an interpretable mechanism to explicitly model the relevant relations among people in the scene, and thus the capability of discriminating different group activities.
group activity recognition을 위해, 동시에 actors 사이의 appearance 와 position relation 을 캡처하기 위한 flexible 하고 efficient 한 actor relation graph 를 구성하였다. 이것은 scene에 있는 사람들 사이의 relevant relation을 명시적으로 모델링하는 해석 가능한 메커니즘을 제공하므로 다양한 그룹 활동을 구별할 수 있다.
- We introduce an efficient inference scheme over the actor relation graphs by applying the GCN with sparse temporal sampling strategy. The proposed network is able to conduct relational reasoning over actor interactions for the purpose of group activity recognition.
sparse temporal sampling 전략을 사용한 GCN을 적용하여 actor relation graph에 대한 효과적인 추론 방식을 소개했다. 제안된 네트워크는 group activity recognition을 위해 actor interaction에 대한 관계적 추론을 수행할 수 있다.
- The proposed approach achieves the state-of-the-art results on two challenging benchmarks: the Volleyball dataset [25] and the Collective Activity dataset [7]. Visualizations of the learned actor graphs and relation features show that our approach has the ability to attend to the relation information for group activity recognition.
Volleyball dataset과 Collective Activity dataset에서 SOTA 달성 하였다. 학습된 actor graph와 relation feature에 대한 visualization은 논문의 접근 방식이 group activity recognition을 위한 관계 정보에 주의를 기울이는 능력을 가지고 있음을 보여준다.
3. Approach
Our goal is to recognize group activity in multi-person scene by explicitly exploiting relation information. To this end, we build Actor Relation Graph (ARG) to represent multi-person scene, and perform relational reasoning on it for group activity recognition.
3.1 Group Activity Recognition Framework
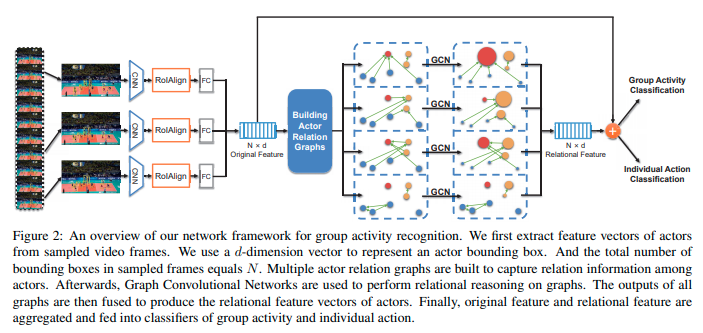
Given a video sequence and the bounding boxes of the actors in the scene, our framework takes three key steps.
- First, we uniformly sample a set of K frames from the video and extract feature vectors of actors from sampled frames. We follow the feature extraction strategy used in [3], which adopts Inception-v3 [51] to extract a multiscale feature map for each frame. We apply RoIAlign [19] to extract the features for each actor bounding box from the frame feature map.
- After that, a fc layer is performed on the aligned features to get a d dimensional appearance feature vector for each actor. The total number of bounding boxes in K frames is denoted as N. We use a N × d matrix X to represent feature vectors of actors.
- Afterwards, upon these original features of actors, we build actor relation graphs, where each node denotes an actor. Each edge in the graphs is a scalar weight, which is computed according to two actors’ appearance features and their relative location. To represent diverse relation information, we construct multiple relation graphs from a same set of actors features.
- Finally, we perform learning and inference to recognize individual actions and group activity. We apply the GCN to conduct relational reasoning based on ARG. After graph convolution, the ARGs are fused together to generate relational representation for actors, which is also in N × d dimension. Then two classifiers respectively for recognizing individual actions and group activity will be applied on the pooled actors’ relational representation and the original representation.
3.2 Building Actor Relation Graphs
Graph definition
Formally, the nodes in our graph correspond to a set of actors , where N is the number of actors, is actor i`s appearance feautre, and is the center cordinates of actors i`s bounding box.
We construct graph to represent pair-wise relation among actors, where relation value indicates the importance of actor j’s feature to actor i.
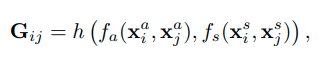
where denotes the appearance relation between two actors, and the position relation is computed by . The function h fuses appearance and position relation to a scalar weight.
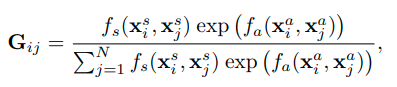
Appearance relation
(1) Dot-Product
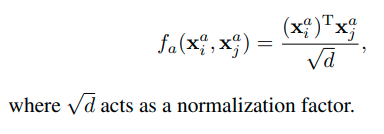
(2) Embedded Dot-Product

(3) Relation Network

Position relation
(1) Distance Mask
Generally, signals from local entities are more important than the signals from distant entities. And the relation information in the local scope has more significance than global relation for modeling the group activity. Based on these observations, we can set as zero for two actors whose distance is above a certain threshhold.

(2) Distance Encoding
Alternatively, we can use the recent approaches [54] for learning position relation.
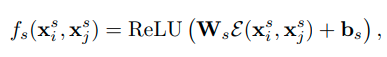
The relative distance between two actors is embedded to a high-dimensional representation by , using cosine and sine functions of different wavelengths. The feature dimension after embedding is.
Multiple graphs
A single ARG typically focuses on a specific relation signal between actors, therefore discarding a considerable amount of context information. In order to capture diverse types of relation signals, we can extend the single actor relation graph into multiple graphs. That is, we build a group of graphs on a same actors set,where is the number of graphs. Building multiple relation graphs allows the model to jointly attend to different types of relation between actors.
Temporal modeling
Temporal context information is a crucial cue for activity recognition. Our model merges the information in the temporal domain via a sparse temporal sampling strategy [58]. During training, we randomly sample a set of K = 3 frames from the entire video, and build temporal graphs upon the actors in these frames.
We call the resulted ARG as randomized ARG.
At testing time, we can use a sliding window approach, and the activity scores from all windows are mean pooled to form global activity prediction. Empirically we find that sparsely sampling frames when training yields significant improvements on recognition accuracy. A key reason is that, existing group activity recognition datasets (e.g., Collective Activity dataset and Volleyball dataset) remain limited, in both size and diversity.
Therefore, randomly sampling the video frames results in more diversity during training and reduces the risk of overfitting. Moreover, this sparse sampling strategy preserves temporal information with dramatically lower cost, thus enabling end-to-end learning under a reasonable budget in both time and computing resources.
sparsely sampling frame의 좋은 점.
3.3 Reasoning and Training on Graphs
Once the ARGs are built, we can perform relational reasoning on them for recognizing individual actions and group activity. After GCN, the way to fuse a group of graphs together remains an open question. In this work, we employ the late fusion scheme, namely fuse the features of same actor in different graphs after GCN:
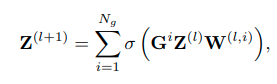
where we employ element-wise sum as a fusion function. + concatenation 을 fusion function 으로도 사용하였고, GCN 이전에 summation 을 통하여 early fusion 으로 융합할 수도 있어서 이에 대한 비교도 실행하였다.
Finally the output relational features from GCN are fused with original features via summation to form the scene representation.
The whole model can be trained in an end-to-end manner with backpropagation. Combining with standard crossentropy loss, the final loss function is formed as
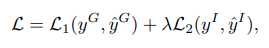
where and are the cross-entropy loss, and denote the ground-truth labels of group activity and individual action, and are the predictions to group activity and individual action.
The first term corresponds to group activity classification loss, and the second is the loss of the individual action classification. The weight λ is used to balance these two tasks.
4. Experiments
4.1 Datasets and Implementation Details
Datasets.
We conduct experiments on two publicly available group activity recognition datasets, namely the Volleyball dataset and the Collective Activity dataset.
The Volleyball dataset [25] is composed of 4830 clips gathered from 55 volleyball games, with 3493 training clips and 1337 for testing. Each clip is labeled with one of 8 group activity labels (right set, right spike, right pass, right winpoint, left set, left spike, left pass and left winpoint).
Only the middle frame of each clip is annotated with the players’ bounding boxes and their individual actions from 9 personal action labels (waiting, setting, digging, failing, spiking, blocking, jumping, moving and standing).
Following [24], we use 10 frames to train and test our model, which corresponds to 5 frames before the annotated frame and 4 frames after. To get the ground truth bounding boxes of unannotated frames, we use the tracklet data provided by [3].
tracklet : 짧은 구간에서의 경로
The Collective Activity dataset [7] contains 44 short video sequences (about 2500 frames) from 5 group activities (crossing, waiting, queueing, walking and talking) and 6 individual actions (NA, crossing, waiting, queueing, walking and talking). The group activity label for a frame is defined by the activity in which most people participate. We follow the same evaluation scheme of [39] and select 1/3 of the video sequences for testing and the rest for training.
Implementation details.
Due to memory limits, we train our model in two stages:
(1) First, we fine-tune the ImageNet pre-trained model on single frame randomly selected from each video without using GCN. The base model performs group activity and individual action classification on original features of actors without relational reasoning.
(2) Then we fix weights of the feature extraction part of network, and further train the network with GCN.
4.2 Ablation Studies
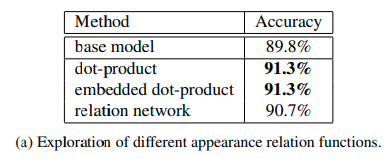
Appearance relation.
Based on single frame, we build single ARG without using position relation.
Position relation.
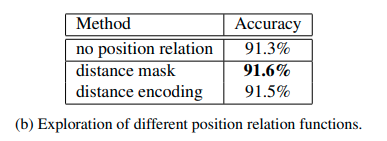
We further add spatial structural information to ARG.
Multiple graphs.
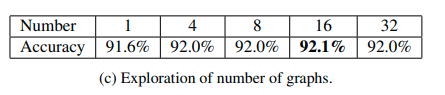
We also investigate the effectiveness of building a group of graphs to capture different kinds of relation information. First, we compare the performance of using different number of graphs.
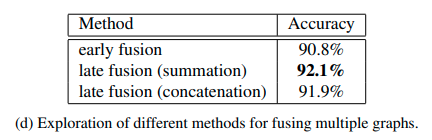
Then we evaluate three methods to fuse a group of graphs: (1) early fusion, (2) late fusion via summation, (3) late fusion via concatenation.
Temporal modeling.
With all the design choices set, we now extend our model to temporal domain. We employ sparse temporal sampling strategy [58], and uniformly sample a set of K = 3 frames from the entire video during training.
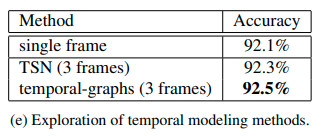
TSN : We can handle the input frames separately, then fuse the prediction scores of different frames as Temporal Segment Network (TSN).
4.3 Comparison with the State of the Art
We train a Faster-RCNN [42] with training data. Using the bounding boxes from Faster-RCNN at testing time, our model can still achieve promising accuracy.
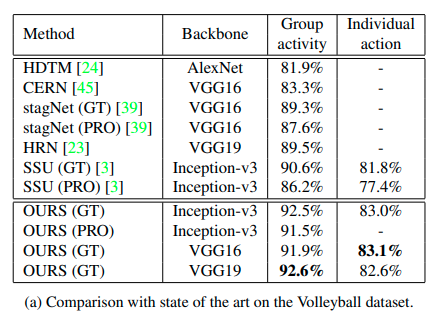
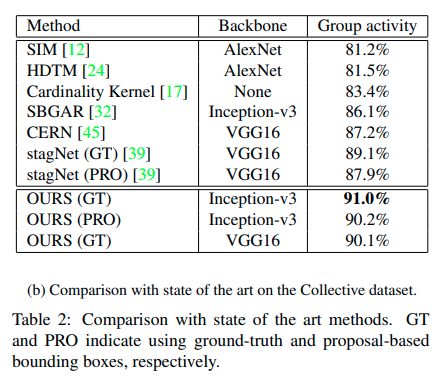
4.4 Model Visualization
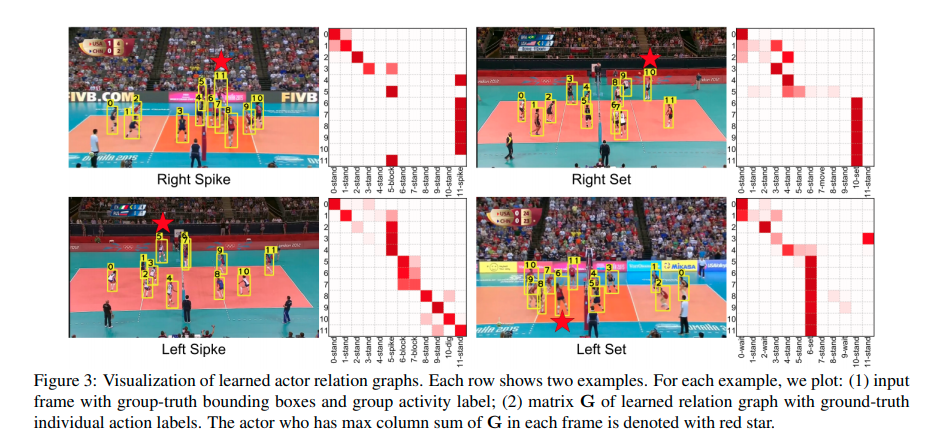
Actor relation graph visualization
We visualize several examples of the relation graph generated by our model in Figure 3. We use the single graph model on single frame, because it is easier to visualize. We can see that our model is able to capture relation information for group activity recognition, and the generated ARG can automatically discover the key actor to determine the group activity in the scene.
t-SNE visualization of the learned representation
Figure 4 shows the t-SNE [53] visualization for embedding the video representation learned by different model variants. Building multiple graphs and aggregating temporal information lead to better differentiate group activities.

5. Conclusion
This paper has presented a flexible and efficient approach to determine relevant relation between actors in a multi-person scene.
We learn Actor Relation Graph (ARG) to perform relational reasoning on graphs for group activity recognition.
We also evaluate the proposed model on two datasets and establish new state-of-the-art results.
The comprehensive ablation experiments and visualization results show that our model is able to learn relation information for understanding group activity.
In the future, we plan to further understand how ARG works, and incorporate more global scene information for group activity recognition.
- 학부생 때 만든 것이라 오류가 있거나, 설명이 부족할 수 있습니다.
Uploaded by N2T
'Paper Summary' 카테고리의 다른 글
| Graph Attention Networks, ICLR’18 (0) | 2023.03.26 |
|---|---|
| GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs, UAI’18 (0) | 2023.03.26 |
| Mesh Graphormer, ICCV’21 (0) | 2023.03.26 |
| Actor-Transformers for Group Activity Recognition, CVPR’20 (0) | 2023.03.26 |
| End-to-end Recovery of Human Shape and Pose, CVPR’18 (0) | 2023.03.26 |