논문 링크 : https://www.cvlibs.net/publications/Peng2020ECCV.pdf
1. Introduction
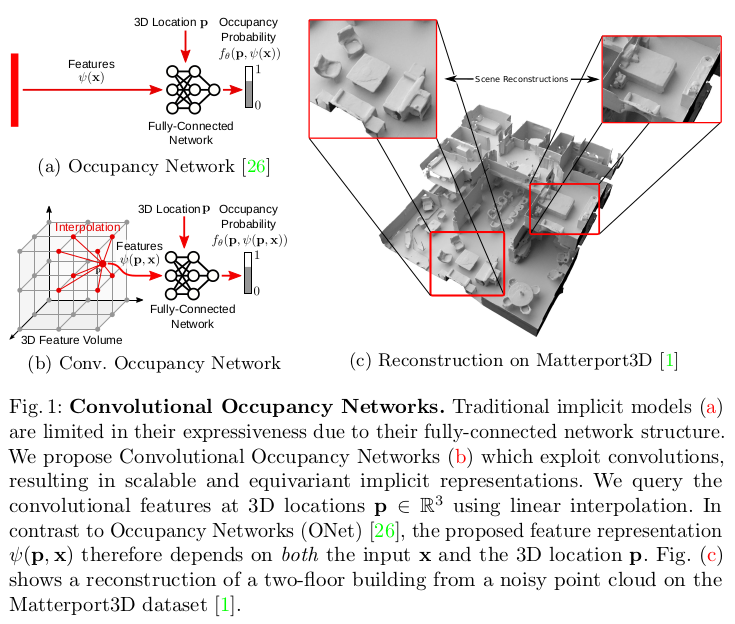
Towards this goal, we introduce Convolutional Occupancy Networks, a novel representation for accurate large-scale 3D reconstruction with continuous implicit representations (Fig. 1). We demonstrate that this representation not only preserves fine geometric details, but also enables the reconstruction of complex indoor scenes at scale. Our key idea is to establish rich input features, incorporating inductive biases and integrating local as well as global information. We systematically investigate multiple design choices, ranging from canonical planes to volumetric representations.
- 본 논문에서는 Convolutional Occupancy Networks 라는 연속적인 implicit representation을 사용하여 정확한 large-scale 3D reconstruction을 위한 novel representation 을 소개한다. 여기서 이 representation이 세밀한 geometric detail을 보존할 뿐만 아니라, 복잡한 내부 장면을 대규모로 재구성할 수 있음을 보여준다. Key idea는 inductive biases를 통합하고, local 정보와 global 정보를 통합하여 유의한 input feature를 만드는 것이다. 저자는 canonical planes로 부터 volumetric representation까지 체계적으로 다양한 design choices를 조사한다.
- Inductive bias란, 학습 시에는 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용하는 추가적인가정 (additional assumptions)을 의미
Contribution
– We identify major limitations of current implicit 3D reconstruction methods. – We propose a flexible translation equivariant architecture which enables accurate 3D reconstruction from object to scene level. – We demonstrate that our model enables generalization from synthetic to real scenes as well as to novel object categories and scenes.
- 현재의 implicit 3D reconstruction methods의 주요 한계 식별
- object 부터 scene level 까지 정확한 3D reconstruction을 가능하게 하는 유연한 translation equivariant architecture(CNN 특징) 제안
- 모델이 synthetic으로 부터 real scene 뿐 아니라 novel object category와 scene 까지도 일반화할 수 있음을 보여줌
+) translation equivariant 는 input value의 위치가 변함에 따라 feature map value도 변하는 것이다. 즉, CNN의 특징중 하나이다. 반대로, max pooling은 특정한 경우에 input value의 위치가 바뀌어도 output value는 같은 경우가 있어 항상 translation equivariant 하지는 않다.
3. Method
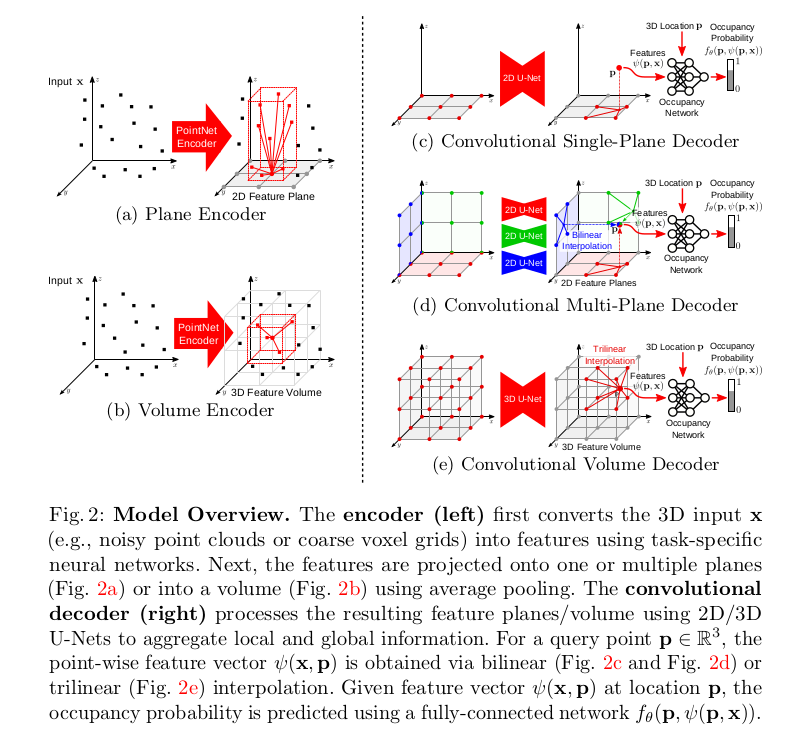
Our goal is to make implicit 3D representations more expressive. An overview of our model is provided in Fig. 2. We first encode the input x (e.g., a point cloud) into a 2D or 3D feature grid (left). These features are processed using convolutional networks and decoded into occupancy probabilities via a fully-connected network.
- 본 논문의 목표는 implicit 3D representation을 더 expressive하게 만드는 것이다. model의 overview는 figure 2와 같다. 먼저, input x를 2D 또는 3D feature grid로 encoding 한다. 그리고 나서 feature를 convolutional network를 통과시키고 fc network를 통해 occupancy probability로 decoding된다.
3.1 Encoder
While our method is independent of the input representation, we focus on 3D inputs to demonstrate the ability of our model in recovering fine details and scaling to large scenes. More specifically, we assume a noisy sparse point cloud (e.g., from structure-from-motion or laser scans) or a coarse occupancy grid as input x.
- 논문의 방법은 input representation과 독립적이지만, 3D input에 초점을 맞춰 detail을 복구하고 large scene으로 확장하는 모델의 능력을 보여준다. 구체적으로, noisy sparse point cloud 또는, coarse(거친) occupancy grid를 input x로 가정한다.
Plane Encoder:
fig 2(a)에 설명되어 있음.
We perform an orthographic projection onto a canonical plane (i.e., a plane aligned with the axes of the coordinate frame) which we discretize at a resolution of H × W pixel cells. For voxel inputs, we treat the voxel center as a point and project it to the plane. We aggregate features projecting onto the same pixel using average pooling, resulting in planar features with dimensionality H × W × d, where d is the feature dimension.
- Plane Encoder는 Resolution size H x W의 pixel cell인 canonical plane으로 orhographic projection을 수행한다. 여기서, plane은 coordinate frame의 axes에 맞추어 정렬되어있다. voxel input에 대해 voxel center를 점으로 취급하여 평면에 projection한다. 추가적으로, average pooling을 사용하여 동일한 pixel에 투영되는 feature를 aggregation하여 dimension이 H x W x d 인 planar feature를 생성한다. 여기서 d는 feature dimension이다. 실험에서는 2가지의 경우를 제시하는데 하나는 ground plane에 projection 하는 것, 그리고 나머지는 3개의 canonical plane에 projection 하는 방법을 제시한다. 첫 번째가 computation이 훨씬 효율적이지만, 두 번째는 geometric structure를 더 잘 recovering 할 수 있다.
Volume Encoder:
While planar feature representations allow for encoding at large spatial resolution (128 pixels and beyond), they are restricted to two dimensions. Therefore, we also consider volumetric encodings (see Fig. 2b) which better represent 3D information, but are restricted to smaller resolutions (typically 32 voxels in our experiments). Similar to the plane encoder, we perform average pooling, but this time over all features falling into the same voxel cell, resulting in a feature volume of dimensionality H × W × D × d.
- Planar feature representation은 큰 resolution에서 encoding을 하지만 2 차원으로 제한된다. 그러므로, 3D information을 더 잘 표현하는 volumetric encoding도 고려하는데 이는 resolution size가 일반적으로 실험해서 32 로 제한된다. plane encoder와 비슷하게, average pooling을 수행하는데, 이번에는 동일한 voxel cell에 속하는 모든 피쳐에 대해 H x W x D x d 차원의 feature volume이 생성된다.
3.2 Decoder
We endow our model with translation equivariance by processing the feature planes and the feature volume from the encoder using 2D and 3D convolutional hourglass (U-Net) networks [6, 39] which are composed of a series of down- and upsampling convolutions with skip connections to integrate both local and global information. We choose the depth of the U-Net such that the receptive field becomes equal to the size of the respective feature plane or volume.
- 논문에서는 model에 translation equivariance를 부여하기위해 encoder의 feature plane과 feature volume을 2D 와 3D convolutional hourglass (U-Net) network를 사용한다. U-Net은 local 및 global 정보를 통합하기 위해 skip connection과 함께 down 및 umsampling convolution으로 구성되어 있다. 여기서, receptive field가 feature plane이나 volume의 크기와 같아지도록 U-Net의 depth를 선택한다.
Our single-plane decoder (Fig. 2c) processes the ground plane features with a 2D U-Net. The multi-plane decoder (Fig. 2d) processes each feature plane separately using 2D U-Nets with shared weights. Our volume decoder (Fig. 2e) uses a 3D U-Net. Since convolution operations are translational equivariant, our output features are also translation equivariant, enabling structured reasoning. Moreover, convolutional operations are able to “inpaint” features while preserving global information, enabling reconstruction from sparse inputs.
- Fig. 2c에 표현된 single-plane decoder는 ground plane feature를 2D U-Net으로 처리한다. Fig 2d의 multi-plane decoder는 각 feature plane을 share weight를 사용하여 개별적으로 2D U-Net을 처리한다. 마지막으로 2e의 volume decoder는 3D U-Net을 사용한다. convolution operation이 translational equivariant 하기 때문에, output feature도 동일하게 translation equivariant 하여 구조적인 추론이 가능하다. 게다가, convolution 연산이 global 정보를 보존하면서 feature를 inpaint할 수 있으므로 sparse input에서 reconstruction이 가능하다. (대략적으로는, global 정보를 보존하므로 sparse input에서 local한 feature들을 잘 연결할 수 있다는 뜻으로 생각됨.)
3.3 Occupancy Prediction
Given the aggregated feature maps, our goal is to estimate the occupancy probability of any point p in 3D space. For the single-plane decoder, we project each point p orthographically onto the ground plane and query the feature value through bilinear interpolation (Fig. 2c). For the multi-plane decoder (Fig. 2d), we aggregate information from the 3 canonical planes by summing the features of all 3 planes. For the volume decoder, we use trilinear interpolation (Fig. 2e).
- Aggregation된 feature map이 주어지면 그 뒤의 목표는 3D 공간에서의 임의의 점 P에 대해 occupancy probability를 추정하는 것이다. single-plane decoder의 경우 각 점 p를 ground plane에 orthographically projection하고 bi-linear interpolation을 통해 feature 값을 query(추정의 의미로 사용되는 듯 함.)한다. multi-plane decoder에서는 3개의 canonical plane으로 부터의 정보를 summation 하는 방식을 사용하였고, volume decoder에서는 tri-linear interpolation을 사용하였음.
Denoting the feature vector for input x at point p as ψ(p, x), we predict the occupancy of p using a small fully-connected occupancy network:
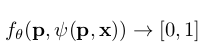
- point p에서 input x에 대한 feature vector를 로 표시하고, fully-connected occupancy network f 를 사용하여 p의 occupancy를 예측한다.
- 아마, 이미 occupy된 input x들에 대해서 임의의 point p가 occupy 되었는지를 체크하는 것 같음.
3.4 Training and Inference
At training time, we uniformly sample query points within the volume of interest and predict their occupancy values. We apply the binary cross-entropy loss between the predicted ô and the true occupancy values :
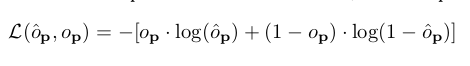
- 학습 시에 관심있는 volume에 대해 sample query point p를 uniform 하게 sampling하고, 그에 대한 occupancy value를 예측한다. Loss로는 예측된 ô 와 gt value 사이에 binary cross-entropy를 적용한다.
As our model is fully-convolutional, we are able to reconstruct large scenes by applying it in a “sliding-window” fashion at inference time.
- 이 모델은 fully-convolution 이므로 inference 시에 "sliding-window" 방식으로 적용하여 large scene을 reconstruction 할 수 있다.
4. Experiments
We conduct three types of experiments to evaluate our method. First, we perform object-level reconstruction on ShapeNet [2] chairs, considering noisy point clouds and low-resolution occupancy grids as inputs. Next, we compare our approach against several baselines on the task of scene-level reconstruction using a synthetic indoor dataset of various objects. Finally, we demonstrate synthetic-to-real generalization by evaluating our model on real indoor scenes [1, 7].
- model을 평가하기 위해 세 가지 유형의 실험을 수행한다. 먼저, noisy point cloud와 low-resolution occupancy grid를 input으로 고려하여 ShapeNet 의자에 대해 object-level reconstruction을 수행한다. 다음으로 다양한 object에 대한 synthetic indoor dataset 을 사용하여 scene-level reconstruction task에 대한 여러 baseline과 approach를 비교한다. 마지막으로, real indoor scene에서 model을 평가하여 synthetic-to-real generalization을 정의한다.
Datasets:
ShapeNet
ShapeNet 에서 13 class 를 사용하였다.
Synthetic Indoor Scene Dataset
ShapeNet의 여러 objects로 5000개의 scene에 대한 synthetic dataset을 생성. Scene은 무작위로 샘플링된 너비 길이 비율이 있는 ground plane, random rotation 및 scale이 있는 여러 object, random하게 샘플링된 벽으로 구성된다.
ScanNet v2
이 dataset에는 RGB-D 카메라로 캡처한 1513개의 실제 방이 포함되어 있다. 테스트를 위해 제공된 mesh에서 point cloud를 샘플링한다.
Matterport3D
Matterport3D에는 Matterport Pro 카메라를 사용하여 캡처한 서로 다른 층에 여러 개의 방이 있는 90개의 빌딩이 있다. ScanNet과 유사하게 Matterport3D에서 모델을 평가하기 위해 point cloud를 샘플링한다.
Baselines:
ONet
Occupancy Networks는 SOTA implicit 3D reconstruction model이다. 이는 fully-connected network architecture와 input에 대한 global encoding을 사용한다.
PointConv
PointNet++ 을 사용하여 point-wise feature를 추출하고 이를 Gaussian kernel regression을 사용하여 interpolating한 후에 이를 동일한 fully-connected network에 통과시켜 또 다른 simple baseline을 구성한다. 이 baseline은 local 정보를 사용하지만 convolution을 이용하지 않는다.
SPSR
SPSR은 point cloud에서 작동하는 전통적인 3D reconstruction 기술이다. 다른 모든 방법과 달리 SPSR에서는 실제 시나리오에서 종종 얻기 어려운 추가적인 surface normal(법선)이 필요하다.
Metrics:
평가 지표로는 Volumetric IoU, Chamfer Distance, Normal Consistency를 사용한다. 추가로 default threshold value가 1%인 F-Score로 report 한다.
4.1 Object-Level Reconstruction
We first evaluate our method on the single object reconstruction task on ShapeNet [2]. We consider two different types of 3D inputs: noisy point clouds and low-resolution voxels. For the former, we sample 3000 points from the mesh and apply Gaussian noise with zero mean and standard deviation 0.05. For the latter, we use the coarse 32 voxelizations from [26].
- 먼저, ShapeNet에서 single object reconstruction task에 대해 평가하였다. noisy point cloud와 low-resolution voxel이라는 두 가지 유형의 3D input을 고려한다. 전자의 경우 mesh에서 3000개 point를 샘플링하고 평균이 0이고 표준 편차가 0.05인 Gaussian noise를 적용한다. 후자의 경우 coarse voxelization을 사용한다.
Reconstruction from Point Clouds:
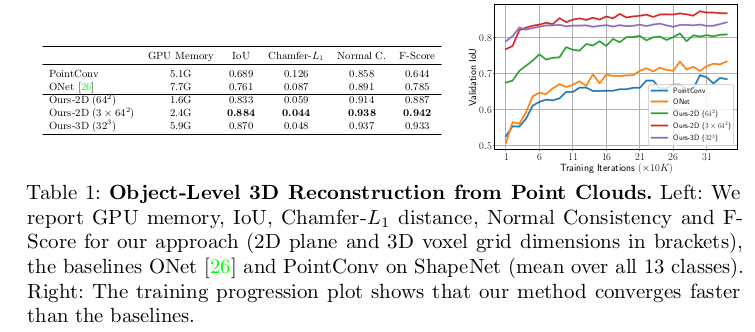
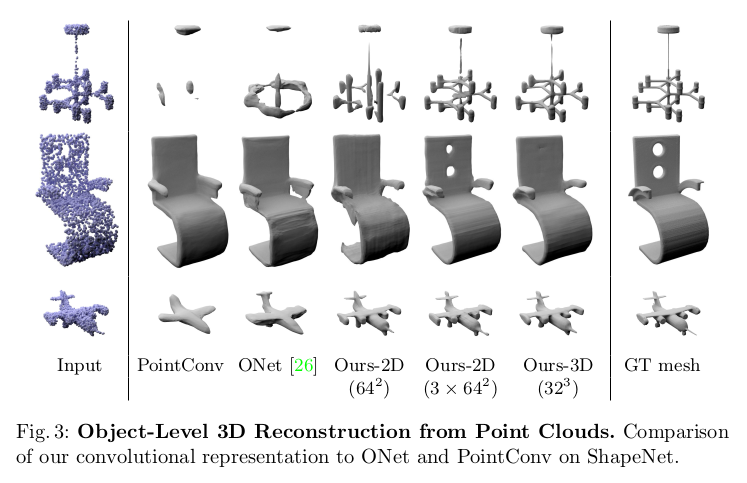
- Baseline과 비교해 보든 measure에 대해 논문에서 제시한 method가 동일하거나 더 나은 결과를 보인다. 우측에는 논문에서 제시한 방법이 몇 번 iteration을 돌지 않았음에도 학습 중에 높은 validation IoU를 달성했다는 것을 보여준다. 그리고 GPU memory를 보면 연산이 훨씬 효율적으로 작동한다는 것을 알 수 있다.
Voxel Super-Resolution:
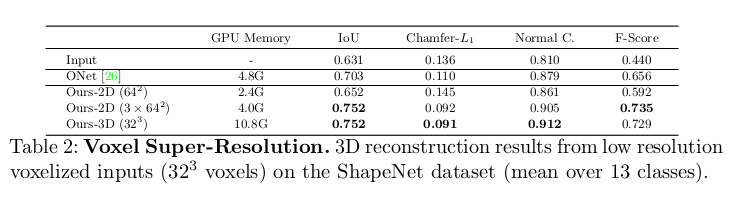
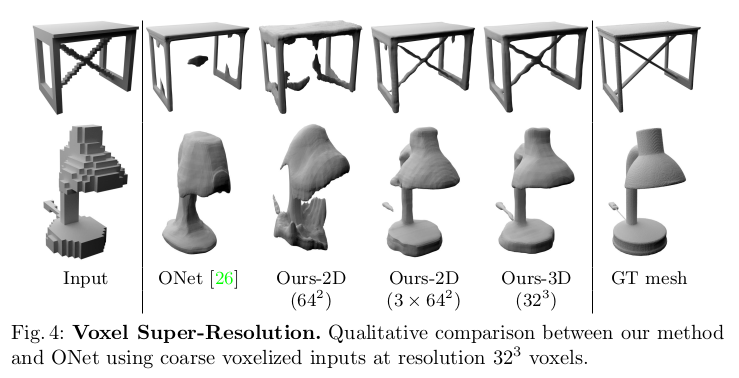
- noisy point cloud에도, voxel super-resolution task에 대한 평가도 하였다. 이 task의 목적은 shape에 대한 coarse() voxelization으로 부터 high-resolution detail을 복원하는 것이다. Table2를 보면 실험결과를 볼 수 있는데 가장 좋은 결과는 volumetric method에서 나왔지만, 3개의 plane을 사용한 method에서 volumetric method의 37% 만큼의 GPU 사용량을 가지고도 비교할만한 결과를 보이고있다.
4.2 Scene-Level Reconstruction
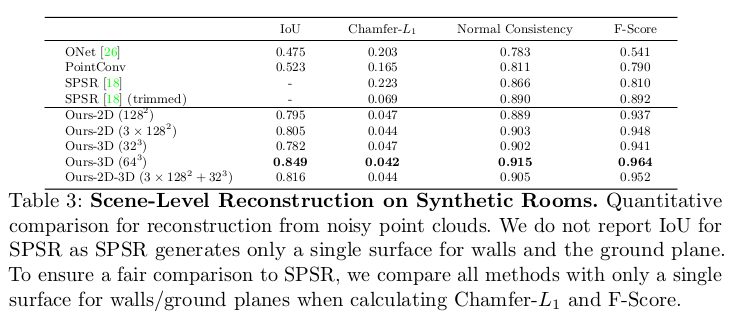

- 다음은 Scene-Level Reconstruction task에 대한 실험 결과이다. 논문에서 제시한 모든 method들이 좋은 결과를 보였다.
4.3 Ablation Study
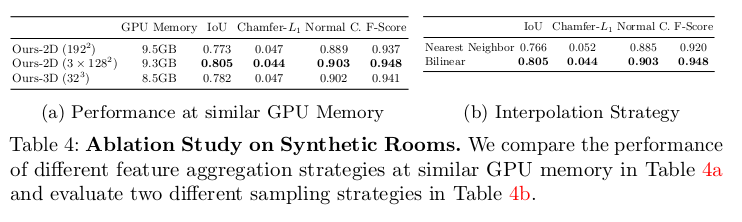
- Table 4a는 유사한 GPU 메모리 사용률에서 다양한 전략을 비교한 것이다. 3 x 128 이 가장 높은 성능을 보였다. 그리고 single plane에서는 resolution을 더 키웠는데 이는 명확한 성능 향상으로 이어지지 않으며, 이는 더 높은 resolution이 반드시 더 나은 성능을 보장하지 않는다는 것을 보인다.
- Table 4b는 feature interpolation 전략에 대해 설명한다. 여기서 Nearest Neighbor 방법과 Bi-linear 방법에 대한 결과인데 Bi-linear 방법이 훨씬 좋은 성능을 보인다.
4.4 Reconstruction from Point Clouds on Real-World Datasets


- 마지막으로, Real-World Dataset에 대한 실험을 제시하는데 위는 ScanNet dataset에 대한 결과이다. Table5는 volumetric-based model이 가장 좋은 성능을 보이는데, 이는 plane 기반의 접근방식이 훨씬 domain shift에 영향을 많이 받는다는 것을 보인다. 그리고 3D CNN이 noise에 대해서 가장 robust함을 저자들이 발견하였다고 한다. 그리고 Matterport3D Dataset에 대한 결과는 fig1에 표현되어있다.
5. Conclusion
We introduced Convolutional Occupancy Networks, a novel shape representation which combines the expressiveness of convolutional neural networks with the advantages of implicit representations. We analyzed the trade-offs between 2D and 3D feature representations and found that incorporating convolutional operations facilitates generalization to unseen classes, novel room layouts and large-scale indoor spaces. We find that our 3-plane model is memory efficient, works well on synthetic scenes and allows for larger feature resolutions. Our volumetric model, in contrast, outperforms other variants on real-world scenarios while consuming more memory.
- Convolutional neural network의 표현력과 implicit representation의 장점을 결합한 novel shape representation인 Convolutional Occupancy Network를 소개하였다. 저자는 2D와 3D feature representation 사이의 trade-off를 분석하였고 convolution 연산을 통합하는 것이 보이지 않는 클래스, novel room layout 및 대규모 실내 공간에 대한 일반화가 용이하다는 것을 발견했다. 그리고 3-plane model이 메모리가 효율적이고 synthetic scene에서 잘 작동하며 더 큰 feature resolution을 허용한다는 것을 발견했다. 대조적으로 volumetric model은 더 많은 메모리를 사용하면서 실제 시나리오에서 robust하다.
Finally, we remark that our method is not rotation equivariant and only translation equivariant with respect to translations that are multiples of the defined voxel size. Moreover, there is still a performance gap between synthetic and real data. While the focus of this work was on learning-based 3D reconstruction, in future work, we plan to apply our novel representation to other domains such as implicit appearance modeling and 4D reconstruction.
- 마지막으로, 논문의 방법은 rotation equivariant 하지 않으며 정의된 voxel size에 대한 배수 변환에만 관련하여 translation equivariant 하다. 또한, synthetic data와 real data 사이에는 여전히 성능 격차가 있다. 이 task의 초점은 학습 기반 3D reconstruction에 있었지만, future work로는 implicit appearance modeling과 4D reconstruction과 같은 다른 영역에 새로운 representation을 적용할 계획이다.
- 학부생 때 만든 것이라 오류가 있거나, 설명이 부족할 수 있습니다.
Uploaded by N2T