Abstract
GCN-based methods are subject to limitations in robustness, interoperability, and scalability. In this work, we propose PoseConv3D, a new approach to skeleton-based action recognition. PoseConv3D relies on a 3D heatmap volume instead of a graph sequence as the base representation of human skeletons. Compared to GCN-based methods, PoseConv3D is more effective in learning spatiotemporal features, more robust against pose estimation noises, and generalizes better in cross-dataset settings. Also, PoseConv3D can handle multiple-person scenarios without additional computation costs.
- 저자는 GCN 기반 방법이 robustness와 interoperability, scalability에 제한이 있음을 문제로 삼으면서, 본 논문에서는 skeleton-based action recognition에 대한 새로운 접근 방식인 PoseConv3D를 제안한다. PoseConv3D는 human skeleton의 base representation으로 graph sequence 대신에 3D heatmap volume을 사용한다. GCN-based method들과 비교하여 PoseConv3D는 spatio-temporal feature를 학습하는 데 더 효과적이며 pose estimation의 noise에 대해 더 robust하고 cross-dataset setting에서 더 잘 generalize 된다. 또한 PoseConv3D는 추가적인 computational cost 없이 multiple-person scenario를 처리할 수 있다.
1. Introduction
GCN based methods are limited in the following aspects:
(1) Robustness: While GCN directly handles coordinates of human joints, its recognition ability is significantly affected by the distribution shift of coordinates, which can often occur when applying a different pose estimator to acquire the coordinates. A small perturbation in coordinates often leads to completely different predictions [66].
(2) Interoperability: Previous works have shown that representations from different modalities, such as RGB, optical flows, and skeletons, are complementary. Hence, an effective combination of such modalities can often result in a performance boost in action recognition. However, GCN is operated on an irregular graph of skeletons, making it difficult to fuse with other modalities that are often represented on regular grids, especially in the early stages. (3) Scalability: In addition, since GCN regards every human joint as a node, the complexity of GCN scales linearly with the number of persons, limiting its applicability to scenarios that involve multiple persons, such as group activity recognition.
- GCN 기반의 방법 지금까지 성공적이었지만, 다음과 같은 측면에서 제한적이다.
- (1) Robustness : GCN은 human joint를 직접적으로 처리하기 때문에 recognition ability는 coordinate의 변화에 크게 영향을 받는다. 이는 joint coordinate를 얻기 위해 다른 pose estimator를 사용했을 경우에 종종 일어나는 현상이다.
- (2) Interoperability : Previous work들은 RGB, optical flow, skeleton과 같은 다양한 modality의 representation이 서로 상호 보완적인 관계임을 보여주었다. 따라서 이러한 것들의 효과적인 combination은 종종 action recognition의 성능 향상을 가져올 수 있다. 그러나, GCN은 skeleton의 graph에서 작동하므로 image grid로 부터 얻을 수 있는 다른 modality와 융합되기 어렵다.
- (3) Scalability : GCN은 모든 human joint를 node로 간주하므로 GCN의 complexity는 사람의 수에 따라서 linear하게 확장되므로 group activity recognition과 같이 multi person이 관련된 scenario에 대한 적용 가능성이 제한된다.

In this paper, we propose a novel framework PoseConv3D that serves as a competitive alternative to GCN based approaches. In particular, PoseConv3D takes as input 2D poses obtained by modern pose estimators shown in Figure 1. The 2D poses are represented by stacks of heatmaps of skeleton joints rather than coordinates operated on a human skeleton graph. The heatmaps at different timesteps will be stacked along the temporal dimension to form a 3D heatmap volume. PoseConv3D then adopts a 3D convolutional neural network on top of the 3D heatmap volume to recognize actions. Main differences between PoseConv3D and GCN-based approaches are summarized in Table 1.
- 본 논문에서는 GCN based method의 대안으로 새로운 framework인 PoseConv3D를 제안한다. 이는 Figure. 1에 표시된 최신의 pose estimator로 얻은 2D pose를 input으로 사용한다. 2D pose는 human skeleton graph에서 작동하는 좌표가 아니라 skeleton joint에 대한 heatmap의 stack으로 표현된다. 서로 다른 시간 축에서의 heatmap은 temporal axis를 따라 stack되어 3D heatmap volume을 형성한다. 그런 다음 PoseConv3D는 3D heatmap volume 위에 3D convolution neural network를 사용해 action을 recognition 한다. PoseConv3D와 GCN-based method의 주요 차이점은 table. 1에 요약되어있다.
PoseConv3D can address the limitations of GCN-based approaches stated above. First, using 3D heatmap volumes is more robust to the up-stream pose estimation: we empirically find that PoseConv3D generalizes well across input skeletons obtained by different approaches. Also, PoseConv3D, which relies on heatmaps of the base representation, enjoys the recent advances in convolutional network architectures and is easier to integrate with other modalities into multi-stream convolutional networks. This characteristic opens up great design space to further improve the recognition performance. Finally, PoseConv3D can handle different numbers of persons without increasing computational overhead since the complexity over 3D heatmap volume is independent of the number of persons. To verify the efficiency and effectiveness of PoseConv3D, we conduct comprehensive studies across several datasets, including FineGYM [43], NTURGB-D [34], UCF101 [51], HMDB51 [26], Kinetics400 [6], and Volleyball [22], where PoseConv3D achieves state-of-the-art performance compared to GCN-based approaches.
- PoseConv3D는 GCN-based method의 한계를 해결할 수 있다. 그 이유로는 첫 째, 3D heatmap volume의 사용은 up-stream pose estimation에 더 강력하다. 저자는 경험적으로 PoseConv3D가 다른 방식들로 얻은 input skeleton 전체에서 잘 generalization 된다는 것을 발견했다. 또한 base representation으로 heatmap에 의지하는 PoseConv3D는 convolution network의 발전과 연관되어있으며 다른 방식과 multi-stream CNN에 통합하기가 더 쉽다. 이 특성은 action recognition performance를 더 향상시킬 수 있는 가능성을 열어준다. 마지막으로, PoseConv3D는 3D heatmap volume의 complexity가 사람의 수와 무관하기 떄문에 computational overhead를 증가시키지 않고 다양한 수의 사람을 처리할 수 있다. 저자는 PoseConv3D의 효율성과 효과를 확인하기 위해 FineGYM [43], NTURGB-D [34], UCF101 [51], HMDB51 [26], Kinetics400 [6], and Volleyball [22]를 포함한 여러 dataset에 실험을 하였고 sota를 달성하였다.
3. Framework
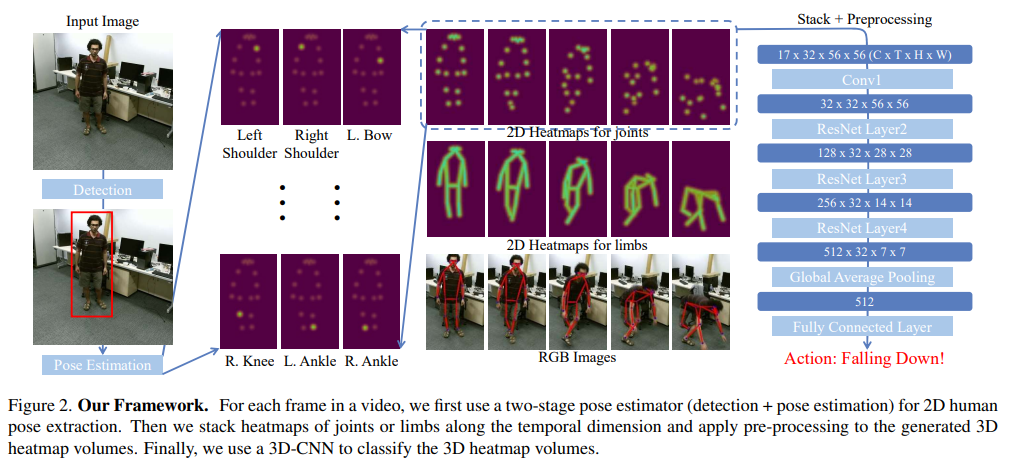
3.1. Good Practices for Pose Extraction
Being a critical pre-processing step for skeleton-based action recognition, human skeleton or pose extraction largely affects the final recognition accuracy. Here we conduct a review on key aspects of pose extraction to find a good practice.
- Skeleton-based action recognition을 위한 중요한 pre-processing step인 human skeleton 또는 pose extraction은 최종 recognition accuracy에 큰 영향을 미친다. 여기서 저자는 모범 사례를 찾기 위해 pose extraction의 key aspects에 대한 review를 수행한다.
In most cases, we feed proposals predicted by a human detector to the Top-Down pose estimators, which is sufficient enough to generate 2D poses of good quality for action recognition. In terms of the storage of estimated heatmaps, they are often stored as coordinate-triplets (x, y, c) in previous literature, where c marks the maximum score of the heatmap and (x, y) is the corresponding coordinate of c. In experiments, we find that coordinate-triplets (x, y, c) help save the majority of storage space at the cost of little performance drop.
- 저자는 human detector에 의해 예측된 proposal를 Top-Down pose estimator에 넣고, action recognition을 위한 좋은 quality의 2D pose를 생성한다. (Bottom-Up은 성능이 별로 안좋음.) 추정된 heatmap의 저장 측면에서, previous work에서 coordinate-triplet인 (x, y, c)로 저장하는데 여기서 c는 heatmap의 maximum score를 표시하고, (x, y)는 c에 해당하는 coordinate를 뜻한다. 실험에서 저자는 coordinate-triplet (x, y, c)가 성능 저하를 최소화 시키면서 대부분의 storage space를 절약하는 데 도움이 된다는 것을 발견했다.
3.2. From 2D Poses to 3D Heatmap Volumes
After 2D poses are extracted from video frames, to feed into PoseConv3D, we reformulate them into a 3D heatmap volume. Formally, we represent a 2D pose as a heatmap of size K × H × W, where K is the number of joints, H and W are the height and width of the frame. We can directly use the heatmap produced by the Top-Down pose estimator as the target heatmap, which should be zero-padded to match the original frame given the corresponding bounding box. In case we have only coordinate-triplets (, , ) of skeleton joints, we can obtain a joint heatmap J by composing K gaussian maps centered at every joint:
- 비디오 frame에서 2D pose를 추출한 후에 PoseConv3D에 input으로 주기 위해 이를 3D heatmap volume으로 재구성한다. 공식적으로, 저자는 2D pose를 heatmap size인 K × H × W 크기의 heatmap으로 표현한다. 여기서 K는 joint 개수이고 H, W는 frame의 height와 width이다. 저자는 Top-Down pose estimator로 부터의 heatmap을 target heatmap으로 직접 사용한다. 이는 해당 bounding box가 있는 original frame과 일치하도록 zero-padding 되어야 한다. Skeleton joint의 coordinate-triplet (, , )이 있는 경우 모든 joint를 중심으로 K개의 gaussian map을 구성하여 joint heatmap J를 얻을 수 있다.
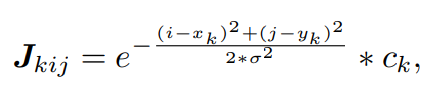
- 여기서 는 gaussian map의 variance를 control 하고, 는 location 는 k 번째 joint의 confidence score이다. (위에는 i,j pixel의 joint heatmap value)
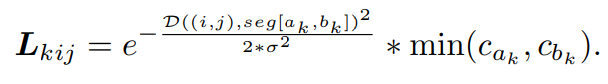
The limb is between two joints and . The function calculates the distance from the point (i, j) to the segment [(, ),(, )]. It is worth noting that although the above process assumes a single person in every frame, we can easily extend it to the multi-person case, where we directly accumulate the k-th gaussian maps of all persons without enlarging the heatmap. Finally, a 3D heatmap volume is obtained by stacking all heatmaps (J or L) along the temporal dimension, which thus has the size of K × T × H × W.
- 그리고 Limb heatmap도 다음과 같이 생성할 수 있다. limb는 두 개의 joint , 사이에 있다. 함수 는 point (i, j)에서 segment [(, ),(, )] 까지의 거리를 계산한다. 위의 프로세스는 모든 프레임에서 single person을 가정하지만, heatmap을 확대시키지 않으면서 모든 사람에 대해 direct하게 k-th gaussian map을 축적함으로써 multi-person case로도 쉽게 확장할 수 있다는 장점이 있다. 마지막으로, 3D heatmap volume은 모든 temporal dimension을 따라 heatmap을 (J 또는 L) stacking함으로써 얻을 수 있고, 이에 대한 size는 K x T x H x W 이다.
In practice, we further apply two techniques to reduce the redundancy of 3D heatmap volumes.
- 학습 과정에서는 3D heatmap volume의 redundancy를 줄이기 위해 2가지의 technique을 사용하였다.
(1) Subjects Centered Cropping.
Making the heatmap as large as the frame is inefficient, especially when the persons of interest only act in a small region. In such cases, we first find the smallest bounding box that envelops all the 2D poses across frames. Then we crop all frames according to the found box and resize them to the target size. Consequently, the size of the 3D heatmap volume can be reduced spatially while all 2D poses and their motion are kept.
- Heatmap을 frame 만큼 크게 만드는 것이 비효율적이다. (특히, subject가 작은 영역에서만 행동하는 경우) 이러한 경우 먼저 frame 전체에서 모든 2D pose를 둘러싸는 가장 작은 bounding box를 찾는다. 그 다음 찾은 bbox에 따라 모든 frame을 자르고 target size로 크기를 조정한다. 결과적으로 모든 2D pose와 motion이 유지되면서 3D Heatmap volume의 크기를 줄일 수 있다.
(2) Uniform Sampling.
The 3D heatmap volume can also be reduced along the temporal dimension by sampling a subset of frames. Unlike previous works on RGB-based action recognition, where researchers usually sample frames in a short temporal window, such as sampling frames in a 64-frame temporal window as in SlowFast [18], we propose to use a uniform sampling strategy [59] for 3D-CNNs instead. In particular, to sample n frames from a video, we divide the video into n segments of equal length and randomly select one frame from each segment. Our empirical studies show that the uniform sampling strategy is significantly beneficial for skeleton-based action recognition.
- 3D heatmap volume은 frame의 subset을 sampling하여 temporal dimension을 따라 줄일 수 있다. SlowFast [18] 처럼 64-frame temporal window 에서 frame을 sampling 하는 것과 같이 researcher가 short temporal window에서 frame을 sampling 하는 RGB-based action recognition인 이전 work와 다르게, 저자는 uniform sampling 을 사용할 것을 제안한다. 특히, 비디오에서 n개의 frame을 sampling 하기 위해 video를 동일한 길이의 n개의 segment로 나누고 각 segment에서 무작위로 하나의 frame을 선택한다. 이는 empirical study로써 uniform sampling이 skeleton-based action recognition에 더 도움이 된다는 것을 보인다.
3.3 3D-CNN for Skeleton-based Action Recognition
To demonstrate the power of 3D-CNN in capturing spatio-temporal dynamics of skeleton sequences, we design two families of 3D-CNNs, namely PoseConv3D for the Pose modality and RGBPose-Conv3D for the RGB+Pose dual-modality.
- Skeleton sequence에 대한 spatio-temporal dynamics를 capturing 하는 3D-CNN의 능력을 증명하기 위해, 저자는 두 가지 3D-CNN 구조를 제안한다. (Pose modality를 위한 PoseConv3D, RGB + Pose dual-modality를 위한 RGBPose-Conv3D.)
PoseConv3D
PoseConv3D focuses on the modality of human skeletons, which takes 3D heatmap volumes as input and can be instantiated with various 3D-CNN backbones. Two modifications are needed to adapt 3D-CNNs to skeleton-based action recognition:
- PoseConv3D는 3D heatmap volume을 input으로 사용하고 다양한 3D-CNN 백본으로 인스턴스화할 수 있는 human skeleton modality에 중점을 둔다. 3D-CNN을 skeleton-based action recognition에 적용하려면 2가지의 수정이 필요하다.
(1) down-sampling operations in early stages are removed from the 3D-CNN since the spatial resolution of 3D heatmap volumes does not need to be as large as RGB clips (4× smaller in our setting);
- 3D heatmap volume의 spatial resolution은 RGB clip만큼 클 필요가 없기 때문에 Early stage에서의 down-sampling operation은 3D-CNN에서 제거된다.
(2) a shallower (fewer layers) and thinner (fewer channels) network is sufficient to model spatiotemporal dynamics of human skeleton sequences since 3D heatmap volumes are already mid-level features for action recognition.
- 더 적은 layer와 적은 channel의 network는 human skeleton sequence에 대한 spatio-temporal dynamics를 modeling하기에 충분한데, 이는 3D heatmap volume이 이미 action recognition을 위한 mid-level feature이기 때문이다.
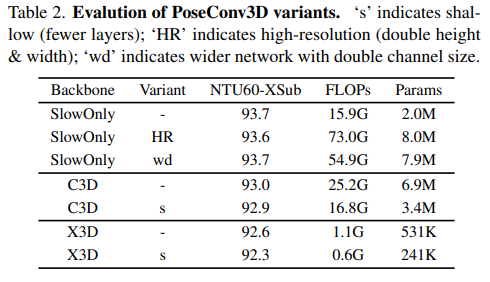
Based on these principles, we adapt three popular 3D-CNNs: C3D [54], SlowOnly [18], and X3D [17], to skeleton-based action recognition (Appendix Table 11 demonstrates the architectures of the three backbones as well as their variants). The different variants of adapted 3D-CNNs are evaluated on the NTURGB+D-XSub benchmark (Table 2). Adopting a lightweight version of 3D-CNNs can significantly reduce the computational complexity at the cost of a slight recognition performance drop (≤ 0.3% for all 3D backbones).
- 이러한 원칙에 따라 저자는 세 가지의 3D-CNN 방식인 C3D, SlowOnly, X3D를 skeleton-based action recognition에 적용한다. 3D-CNN의 경량 버전을 채택하면 약간의 recognition performance 저하를 감수하면서 computational complexity를 크게 줄일 수 있다. 실험에는 단순성과 우수한 인식성능을 고려하여 SlowOnly를 기본 backbone으로 사용한다. (여기서 저자는 제시한 방법의 interoperability 덕분에 multi-modality fusion에 human skeleton을 쉽게 포함할 수 있다는 장점을 주장한다.)
RGBPose-Conv3D.
To show the interoperability of PoseConv3D, we propose RGBPose Conv3D for the early fusion of human skeletons and RGB frames. It is a two-stream 3D-CNN with two pathways that respectively process RGB modality and Pose modality. The architecture of RGBPose-Conv3D follows several principles in general:
- PoseConv3D의 interoperability를 보여주기 위해 human skeleton과 RGB frame의 early fusion을 위한 RGBPose Conv3D를 제안한다. 이는 RGB modality와 pose modality를 각각 처리하는 2개의 경로가 있는 2개의 stream 3D-CNN이다. RGBPose-Conv3D의 architecture는 일반적으로 몇 가지 원칙을 따른다.
(1) the two pathways are asymmetrical due to the different characteristics of the two modalities: Compared to the RGB pathway, the pose pathway has a smaller channel width, a smaller depth, as well as a smaller input spatial resolution.
- 두 개의 경로는 서로 다른 특성으로 인해 asymmetrical 하다. RGB 경로와 비교하여 pose 경로는 더 작은 채널 폭, 더 작은 depth, 더 작은 input spatial resolution을 가지기 때문이다.
(2) Inspired by SlowFast [18], bidirectional lateral connections between the two pathways are added to promote early-stage feature fusion between two modalities. To avoid overfitting, RGBPose-Conv3D is trained with two individual cross-entropy losses respectively for each pathway. In experiments, we find that early-stage feature fusion, achieved by lateral connections, leads to consistent improvement compared to late-fusion only.
- SlowFast로 부터 영감을 받아 두 개의 경로 사이의 bidirectional lateral connection이 추가되어 두 modality 사이의 early-stage feature fusion을 촉진한다. 그리고 overfitting을 피하기 위해 RGBPose-Conv3D는 각 경로에 대해 각각 두 개의 개별 cross-entropy loss로 학습된다. 실험에서 저자는 lateral connection에 의해 달성된 early-stage feature fusion이 late-fusion에 비해 일관되게 improve가 있었다.
4. Experiments
4.1. Dataset Preparation
- FineGYM [43], NTURGB+D [34, 42], Kinetics400 [6, 64], UCF101 [51], HMDB51 [26] and Volleyball [22].
Unless otherwise specified, we use the Top-Down approach for pose extraction: the detector is faster-RCNN [40] with the ResNet50 backbone, the pose estimator is HRNet [53] pre-trained on COCO-keypoint [31].
For all datasets except FineGYM, 2D poses are obtained by directly applying TopDown pose estimators to RGB inputs. We report the Mean Top-1 accuracy for FineGYM and Top-1 accuracy for other datasets. We adopt the 3D ConvNets implemented in MMAction2 [11] in experiments.
4.2. Good properties of PoseConv3D
Performance & Efficiency.
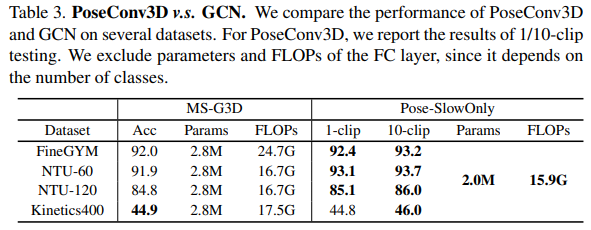
- GCN 기반의 방법론과 저자가 제시한 방법론 사이의 성능 차이를 기술하고 있음. GCN 보다 parameter 수도 적고, FLOPs도 적음. 그리고 1-clip test의 경우에서도 이미 sota이거나 비슷한 수준.
Robustness.
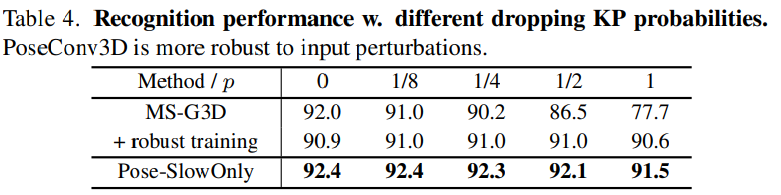
- model의 robustness를 test하기 위해, input keypoint의 비율을 지우고 이러한 왜곡이 최종 정확도에 어떤 영향을 미치는지 확인한다. Limb keypoint는 몸통이나 얼굴 keypoint보다 체조에 더 중요하기 때문에 확률 p로 각 frame에서 하나의 limb keypoint를 임의로 드롭하여 두 모델을 모두 테스트한다. PoseConv3D가 input perturbation에 대해 매우 robust하다는 것을 알 수 있다. frame당 하나의 limb keypoint를 drop시키는 경우 GCN 기반의 방법론에서는 급격하게 떨어지는 반면에 PoseConv3D는 그렇지 않다. (robust training할 경우에도 성능이 본 논문의 방식보다 낮고 92.0 보다 1.4% 떨어진 90.6% 임.)
Generalization.
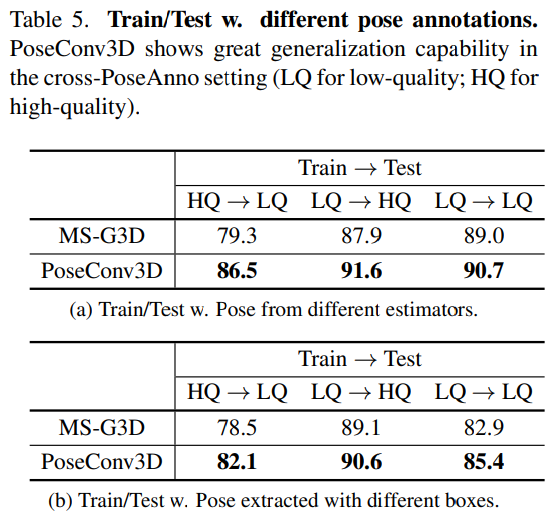
- GCN과 3D-CNN의 generalization 성능의 비교를 위해 FineGYM에서 cross-model check를 진행하였다. (pose estimator로 HQ는 Higher-Quality(HRNet), LQ는 Lower-Quality(MobileNet) / bbox HQ는 GT, LQ는 tracking results라고 함.) (a) Pose estimator의 성능에 따른 performance drop이 PoseConv3D 방법론에서는 덜하다. (b) Bbox의 quality에 따른 performance drop에 대해서도 reporting 하였음.
Scalability.
- GCN의 computation scale은 video에서 사람의 수에 따라서 linear하게 증가한다. PoseConv3D에서는 single heatmap volume에 모든 사람을 표현하므로 확장이 용이하다.
4.3. Multi-Modality Fusion with RGBPose-Conv3D
- PoseConv3D에 대한 3D-CNN architecture는 early fusion 전략을 통해 다른 modality와의 fuse도 유연하게 가능하다. 실제로 먼저 RGB와 Pose modality에 대한 두 가지의 model을 각각 학습시키고 RGBPose-Conv3D를 initialize하는 데 사용한다. 그 다음 lateral connection을 학습하기 위해 fine-tune 시킨다. 최종적인 prediction은 두 경로의 prediction score를 late fusion하여 달성한다. Early+late fusion 둘 다를 사용했을 때 가장 좋은 결과를 달성하였다.
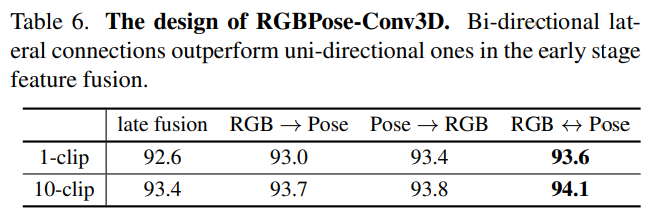
- Lateral Connection에 대한 실험. uni-directional 하게 connection을 짰는지 bi-directional 하게 connection을 짰는지에 대한 실험인데 bi-direction이 성능이 가장 좋았음.
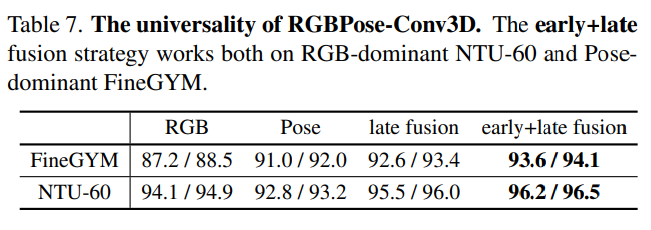
- Early + late fusion을 동시에 사용하는 것이 성능이 가장 좋음.
4.4 Comparisons with the state-of-the-art
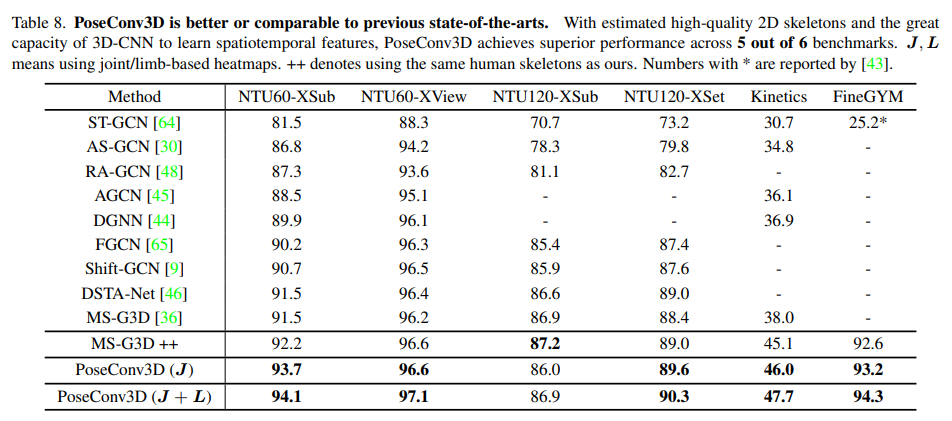
Skeleton-based Action Recognition.
- PoseConv3D가 뛰어난 성능을 보였고, Joint와 Limb를 같이 사용하면 성능이 더 좋았음. 그리고 MS-G3D++ 은 원래 3D skeleton을 쓰는 모델을 바꿔서 저자가 제시한 방법처럼 2D + c (probability) 형태로 사용하였는데 이렇게 사용할 경우 성능이 높아졌음.

Multi-modality Fusion.
- (a)는 RGBPose-Conv3D, 그리고 (b)는 LateFusion 의 경우에서 둘 다 성능이 좋게 나옴. 즉 여기서 (a)는 아까 설명했던 early + late fusion 방식이고, (b)는 Pose modality에다가 rgb나 flow modality를 붙여서 late fusion 한 것.
4.5. Ablation on Heatmap Processing
Subjects-Centered Cropping.
- size와 location은 dataset마다 다양하기 떄문에, action subject에 집중하는 것이 상대적으로 적은 H x W computational cost로 최대한 많은 정보를 가져가는 것이 중요하고, 이를 위해 subject-centered cropping을 한 실험 결과 1% 정도의 성능 향상이 있었음.
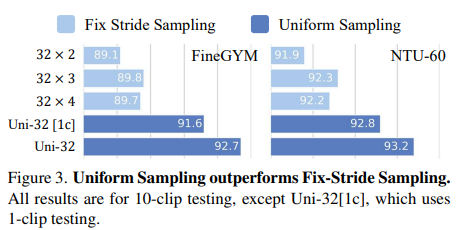
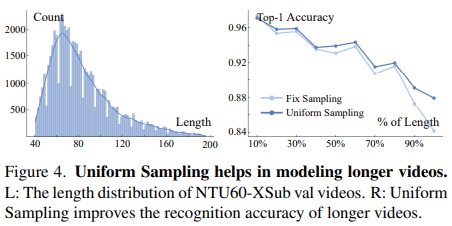
Uniform Sampling.
- 32 x 2 → 32개의 frame을 sampling 하는데 stride 2. Fixed stride를 가지고 sampling 하는 것 보다 uniform sampling 하는 것이 비디오 전체의 dynamics를 잘 capture한다고 말함.
Pseudo Heatmaps for Joints and Limbs.
- GCN 기반의 방식은 일반적으로 성능 향상을 위해 여러 stream (joint, bone 등)의 결과를 ensemble 한다. 이것은 PoseConv3D에서도 가능한데 (x, y, c)를 기반으로 joint와 limb에 대한 pseudo heatmaps를 만들 수 있다. 일반적으로 저자는 joint heatmap과 limb heatmap 모두 3D-CNN에 좋은 input이라는 것을 발견했다. 즉, J + L로 결합하면 눈에 띄고 일관적인 성능 향상을 가져올 수 있다.
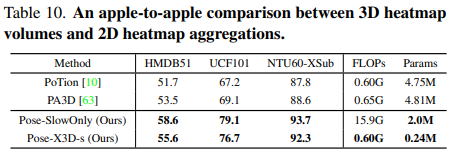
3D Heatmap Volumes vs 2D Heatmap Aggregations.
- 위의 두 가지 방법은 2D Heatmap Aggregation을 input으로 사용하고 아래 2개는 3D Heatmap Volume을 사용함. 특히, X3D-s 같은 경우 더 적은 FLOPs 와 parameter로 높은 성능을 내었음.
5. Conclusion
In this work, we propose PoseConv3D: a 3D CNNbased approach for skeleton-based action recognition, which takes 3D heatmap volumes as input. PoseConv3D resolves the limitations of GCN based approaches in robustness, interoperability, and scalability. With light-weighted 3D-ConvNets and compact 3D heatmap volumes as input, PoseConv3D outperforms GCN-based approaches in both accuracy and efficiency. Based on PoseConv3D, we achieve state-of-the-art on both skeleton-based and multi-modality based action recognition across multiple benchmarks.
- 본 논문에서는 3D Heatmap Volume을 input으로 사용하는 skeleton-based action recognition을 위한 3D-CNN 기반의 method인 PoseConv3D를 제안한다. PoseConv3D는 robustness, interoperability, scalability 측면에서 GCN-based method의 limitation을 해결한다. Light-weighted 3D-ConvNet과 작은 3D heatmap volume을 input으로 사용하는 PoseConv3D는 accuracy와 efficiency 측면에서 GCN-based approach를 능가한다. PoseConv3D를 기반으로 여러 benchmark에서 skeleton-based 및 multi-modality based action recognition 모두에서 sota를 달성했다.
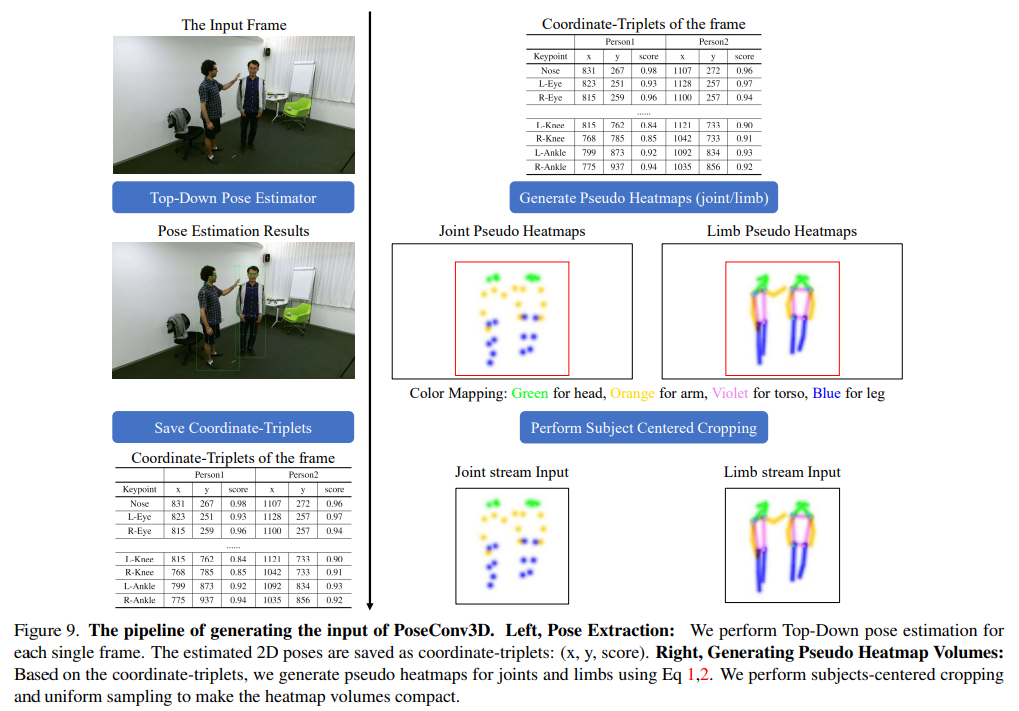
PoseConv3D의 input을 만드는 방법
- 왼쪽 (Pose Extraction) : 각 frame마다 Top-Down pose estimation을 수행. 예측된 2D pose는 coordinate-triplets (x, y, score)로 저장.
- 오른쪽 (Generating Pseudo Heatmap Volumes) : coordinate-triplets를 기반으로 joint와 limb에 대한 pesudo heatmap을 만든다 (Gaussian 사용하는 수식). 이 때 subject-cented cropping과 uniform sampling을 통해 heatmap volume을 compact하게 만들 수 있다.
Uploaded by N2T