1. Introduction
We hypothesize a transformer network can also better model relations between actors and combine actor-level information for group activity recognition compared to models that require explicit spatial and temporal constraints.
A key enabler is the transformer’s self-attention mechanism, which learns interactions between the actors and selectively extracts information that is important for activity recognition.
Besides introducing the transformer in group activity recognition, we also pay attention to the encoding of individual actors.
First, by incorporating simple yet effective positional encoding [55].
Second, by explicit modeling of static and dynamic representations of the actor, which is illustrated in Figure 1.
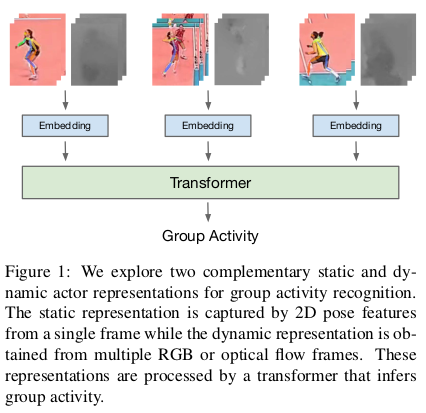
The static representation is captured by pose features that are obtained by a 2D pose network from a single frame.
The dynamic representation is achieved by a 3D CNN taking as input the stacked RGB or optical flow frames.
This representation enables the model to capture the motion of each actor without explicit temporal modeling via RNN or graphical models. Meanwhile, the pose network can easily discriminate between actions with subtle motion differences. Both types of features are passed into a transformer network where relations are learned between the actors enabling better recognition of the activity of the group.
Finally, given that static and dynamic representations capture unique, but complimentary, information, we explore the benefit of aggregating this information through different fusion strategies.
Contribution
- We introduce the transformer network for group activity recognition. It refines and aggregates actor-level features, without the need for any explicit spatial and temporal modeling.
- We feed the transformer with a rich static and dynamic actor-specific representation, expressed by features from a 2D pose network and 3D CNN. We empirically study different ways to combine these representations and show their complementary benefits.
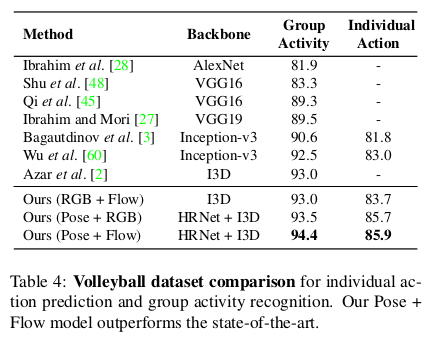
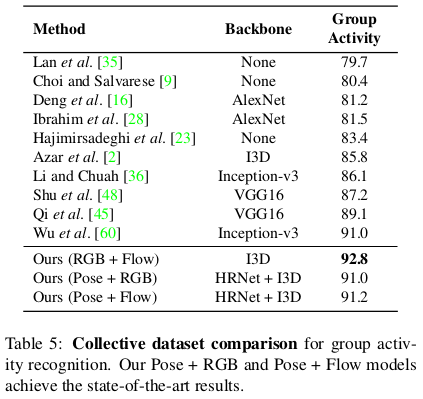
- Our actor transformers achieve state-of-the-art results on two publicly available benchmarks for group activity recognition, the Collective [11] and Volleyball [28] datasets, outperforming the previous best published results [2, 60] by a considerable margin.
3. Model
Our approach consists of three main stages presented in Figure 2: actor feature extractor, group activity aggregation and fusion.
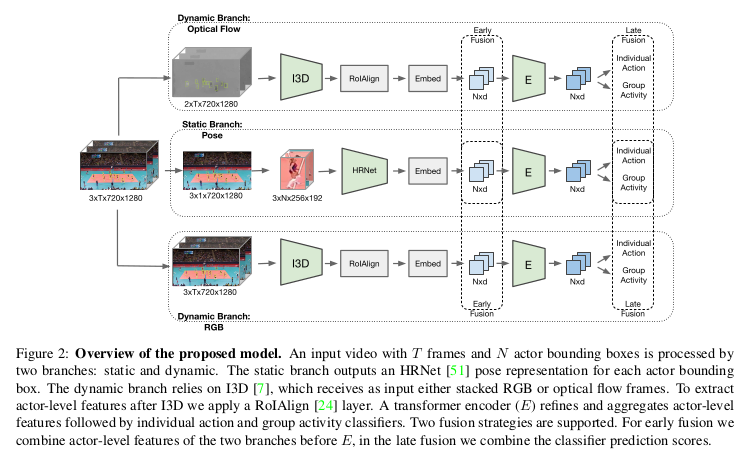
In brief, the input to our model is a sequence of video frames with N actor bounding boxes provided for each frame where T is the number of frames.
We obtain the static and the dynamic representation of each actor by applying a 2D pose network on a single frame and a 3D CNN on all input frames. The dynamic representation can be built from RGB or optical flow frames, which are processed by a 3D CNN followed by a RoIAlign [24] layer.
Next, actor representations are embedded into a subspace such that each actor is represented by a 1-dimensional vector. In the second stage, we apply a transformer network on top of these representations to obtain the action-level features. These features are max pooled to capture the activity-level features. A linear classifier is used to predict individual actions and group activity using the action-level and group activity-level features, respectively.
In the final stage we introduce fusion strategies before and after the transformer network to explore the benefit of fusing information across different representations.
3.1 Actor feature extractor
We utilize two distinct backbone models to capture both position and motion of joints and actors themselves. To obtain joints positions a pose estimation model is applied. It receives as input a bounding box around the actor and predicts the location of key joints.
We select the recently published HRNet [51] as our pose network as it has a relatively simple design, while achieving state-of-the-art results on pose estimation benchmarks.
We use the features from the last layer of the network, right before the final classification layer, in all our experiments.
We utilize the I3D [7] network in our framework since the pose network alone can not capture the motion of the joints from a single frame. We consider RGB and optical flow representations as they can capture different motion aspects.
As 3D CNNs are computationally expensive, we employ a RoIAlign [24] layer to extract features for each actor given N bounding boxes around actors while processing the whole input frames by the network only once.
3.2 Transformer
The self-attention mechanism is the vital component of the transformer network, which can also be successfully used to reason about actors’ relations and interactions.
Formally, attention with the scaled dot-product matching function can be written as:
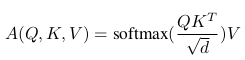
where d is the dimension of both queries and keys.
In the self-attention module all three representations (Q, K, V ) are computed from the input sequence S via linear projections so A(S) = A(Q(S), K(S), V (S)).
Multi-head attention is an extension of attention with several parallel attention functions using separate linear projections of (Q, K, V ):
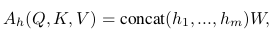
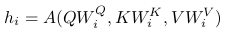
Transformer encoder layer E consists of multi-head attention combined with a feed-forward neural network L:

The transformer encoder can contain several of such layers which sequentially process an input S. In our case S is a set of actors’ features S = {} obtained by actor feature extractors. As features do not follow any particular order, the self-attention mechanism is a more suitable model than RNN and CNN for refinement and aggregation of these features.
However, the graph representation requires explicit modeling of connections between nodes through appearance and position relations. The transformer encoder mitigates this requirement relying solely on the self-attention mechanism. We show that the transformer encoder can benefit from implicitly employing spatial relations between actors via positional encoding of .
We do so by representing each bounding box b i of the respective actor’s features with its center point (, ) and encoding the center point with the same function PE as in [55]. To handle 2D space we encode with the first half of dimensions of and with the second half.
In this work we consider only the encoder part of the transformer architecture leaving the decoder part for future work.
3.3 Fusion
We incorporate several modalities into one framework. The static branch is represented by the pose network which captures the static position of body joints, while the dynamic branch is represented by I3D and is responsible for the temporal features of each actor in the scene. As RGB and optical flow can capture different aspects of motion we study dynamic branches with both representations of the input video.
To fuse static and dynamic branches we explore two fusion strategies:
- Early fusion of actors’ features before the transformer network
- Late fusion which aggregates predictions of classifier
Early fusion enables access to both static and dynamic features before inference of group activity. Late fusion separately processes static and dynamic features for group activity recognition and can concentrate on static or dynamic features, separately.
3.4 Training objective
Our model is trained in an end-to-end fashion to simultaneously predict individual actions of each actor and group activity. For both tasks we use a standard cross-entropy loss for classification and combine two losses in a weighted sum:
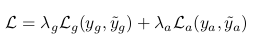
where are cross-entropy losses, and are ground truth labels, and are model predictions for group activity and individual actions, respectively. and are scalar weights of the two losses. We find that equal weights for individual actions and group activity perform best so we set = = 1 in all our experiments, which we detail next.
4. Experiments
4.3 Ablation study
Actor-Transformer
We experiment with the number of layers, number of heads and positional encoding. Only the static branch represented by the pose network is considered in this experiment.
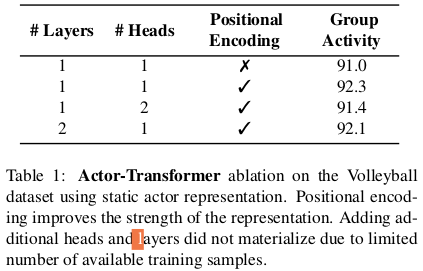
Positional encoding is a viable part giving around 1.3% improvement. This is expected as group activity classes of the Volleyball dataset are divided into two subcategories according to the location of which the activity is performed: left or right.
Typically, transformer-based language models benefit from using more layers and/or heads due to the availability of large datasets. However, the Volleyball dataset has a relatively small size and the transformer can not fully reach its potential with a larger model. Therefore we use one layer with one head in the rest of the experiments.
Actor Aggregation
Next, we compare the actor-transformer with two recent approaches that combine information across actors to infer group activity.

We use a static single frame (pose) and dynamic multiple frames (I3D) models as a baseline.
The first related method uses relational graph representation to aggregate information across actors [60]. The second related method is based on multiple refinement stages using spatial activity maps [2]. For fair comparison, we replace the actor-transformer with a graph and keep the other parts of our single branch models untouched.
Our actor-transformer outperforms the graph for all backbone networks with good improvement for optical flow features without explicitly building any relationship representation. We match the results of activity maps [2] on optical flow and having slightly worse results on RGB. However, we achieve these results without the need to convert bounding box annotations into segmentation masks and without multiple stages of refinement.
- Activity Maps 와 optical flow 에서는 동일한 결과를, RGB 에서는 약간 더 나쁜 결과를 얻는다. 하지만, 이러한 결과는 bounding box annotation 을 segmentation mask 로 변환하는 것과, 여러 단계의 개선 없이도 가능하였다.
Fusion
In the last ablation, we compare different fusion strategies to combine the static and dynamic representations of our model.
For the late fusion, we set the weight for the static representation to be twice as large as the weight for the dynamic representation.
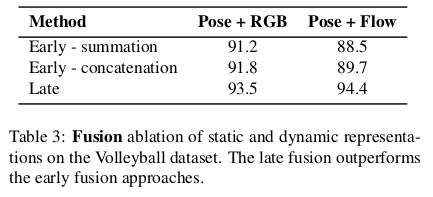
The early fusion is not beneficial for our model, performing similar or even worse than single branch models. Early fusion strategies require the actor-transformer to reason about both static and dynamic features. Due to the small size of the Volleyball dataset, our model can not fully exploit this type of fusion.
- Early fusion 은 우리 모델에서 유익하지는 않는데, 이는 single branch model 과 유사하거나 심지어 더 나쁜 성능을 보이기 때문이다. Early fusion 전략은 actor-transformer 가 static 과 dynamic feature 를 추론하는 것을 필요로 한다. Volleyball dataset 이 너무 작기 때문에, 우리 모델은 이러한 유형의 fusion 을 전부 이용할 수 없다.
Despite Flow only slightly outperforming RGB (91.5% vs. 91.4%), fusion with static representation has a bigger impact (93.9% vs. 93.1%) showing that Flow captures more complementary information to Pose than RGB.
4.4 Comparison with the state-of-the-art
We present two variations of our model, late fusion of Pose with RGB (Pose + RGB) and Pose with optical flow (Pose + Flow).
4.5 Analysis
To analyze the benefits of our actor-transformer we illustrate the attention of the transformer.
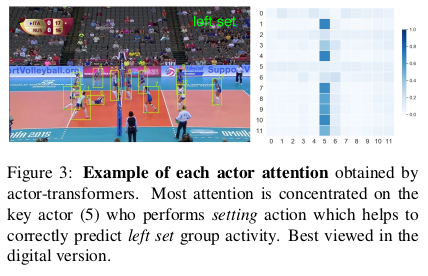
Each row of the matrix on the right represents the distribution of attention in equation 2 using the representation of the actor with the number of the row as a query. For most actors the transformer concentrates mostly on the key actor with number 5 of the left set group activity who performs a setting action.
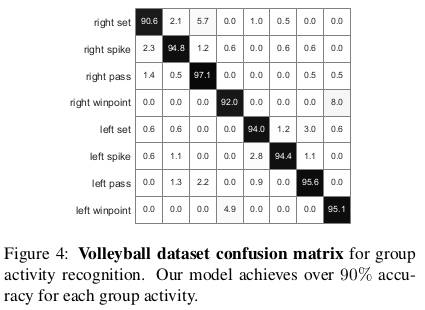
To further understand the performance of our model we also present confusion matrices for group activity recognition on the Volleyball dataset in Figure 4 and the Collective dataset in Figure 5.

5. Conclusion
We proposed a transformer-based network as a refinement and aggregation module of actor-level features for the task of group activity recognition.
We show that without any task-specific modifications the transformer matches or outperforms related approaches optimized for group activity recognition.
Furthermore, we studied static and dynamic representations of the actor, including several ways to combine these representations in an actor-transformer.
We achieve the state-of-the-art on two publicly available benchmarks surpassing previously published results by a considerable margin.
- 학부생 때 만든 것이라 오류가 있거나, 설명이 부족할 수 있습니다.
Uploaded by N2T
'Paper Summary' 카테고리의 다른 글
| Graph Attention Networks, ICLR’18 (0) | 2023.03.26 |
|---|---|
| GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs, UAI’18 (0) | 2023.03.26 |
| Learning Actor Relation Graphs for Group Activity Recognition, CVPR’19 (0) | 2023.03.26 |
| Mesh Graphormer, ICCV’21 (0) | 2023.03.26 |
| End-to-end Recovery of Human Shape and Pose, CVPR’18 (0) | 2023.03.26 |
